


Generative AI adoption is skyrocketing across industries, but organizations face a critical choice in how to deploy these models. Many use third-party cloud AI services (e.g. OpenAI’s APIs) where they pay per token for a hosted model, while others are investing in Private AI – running AI models on-premises or in hybrid private clouds. There is no one-size-fits-all solution: roughly one-third of enterprises use only public cloud AI, one-third use only private infrastructure, and the rest pursue a hybrid approach.
The decision often depends on use case requirements for latency, data control, cost, and compliance. For example, a large bank might want AI-driven fraud detection and personalized advice, but due to the sensitivity of financial data and strict regulations, it opts for a private, on-premises AI deployment to avoid exposing customer data. This report provides an in-depth comparison of Private AI versus cloud-based generative AI along technical, regulatory, economic, and security dimensions. It also examines why many organizations are adopting Private AI and the key challenges in scaling generative AI in practice. Throughout, we cite industry research and expert analysis to highlight the benefits and trade-offs of each approach.
Technical Considerations (Latency, Performance, Integration, Customization)
Latency & Performance: Where the AI model is hosted can significantly impact response times and throughput. Private AI deployments allow organizations to run models close to their data and users, for instance on-premises or at the network edge, yielding low-latency inference. This is crucial for real-time use cases (e.g. interactive assistants, manufacturing robotics) that can’t tolerate the network delays of cloud calls. An Equinix study noted that private AI enables “AI inference at the edge in a secure manner with low latency” – meaning companies can bring the model on-site to avoid sending data over the internet. In contrast, using a cloud API involves sending requests to a remote datacenter and waiting for a response, which adds network latency and potential variability. If the internet connection is slow or the cloud service is rate-limited, performance may suffer. Moreover, performance predictability is an advantage of private deployments: with dedicated on-prem hardware, organizations get consistent throughput and are not subject to multi-tenant resource contention. By self-hosting, “your AI infrastructure behaves predictably – no surprise throttling”, as one practitioner observed. Public cloud models are highly optimized and can scale to heavy workloads, but they may throttle throughput for individual customers or queue requests if usage exceeds certain limits. In summary, Private AI can deliver faster, more consistent responses for local users, whereas cloud AI offers massive scalability but with added network overhead.
Integration & Data Gravity: Enterprises must also consider how easily the AI solution integrates with existing systems and data sources. With an on-premises or hybrid Private AI approach, organizations “move the AI model to where their data exists”, keeping data within internal infrastructure. This aligns with the principle of data gravity – large datasets (e.g. proprietary customer databases or sensitive documents) often already reside in on-prem data lakes or private clouds, so it’s efficient to bring the model to the data rather than shuttling data to an external cloud. Private AI can be tightly integrated behind the firewall, directly interfacing with internal databases and applications. In contrast, cloud-based generative AI requires moving data out to the provider’s environment (or sending it via API calls), which introduces data transfer costs and complexity. As one analysis noted, “moving data in and out of [the] cloud can incur substantial egress charges”, especially for hybrid scenarios. Integration via APIs is certainly possible (and many cloud AI providers offer robust APIs and SDKs), but careful engineering and security measures (encryption, VPNs, etc.) are needed to connect cloud AI with on-prem data sources. In highly distributed organizations, hybrid architectures are emerging – for example, using cloud AI for general knowledge and an on-prem model for sensitive data – but this requires sophisticated orchestration. Overall, Private AI offers tighter integration with local systems and avoids the need to transfer sensitive data, whereas cloud AI provides easy integration with other cloud services and global accessibility (at the cost of moving data to the cloud).
Model Customization: Another technical factor is how much one can customize or fine-tune the AI model. Private AI deployments typically leverage open-source or proprietary models that the organization can modify, fine-tune on domain-specific data, or even extend with new capabilities. This flexibility is a key draw – on-prem lets you “tailor every layer of the stack… no compromises”. For instance, a hospital could fine-tune an open language model on its medical texts to create a specialized clinical assistant, or a financial firm could train a model on its historical trading data. Such deep customization is often not possible with closed cloud AI APIs; providers like OpenAI or Google may allow limited fine-tuning or prompt tuning, but the core model and its training data remain a black box. By self-hosting, enterprises ensure full control over model updates and behavior. They can also choose smaller, faster models targeted to their specific use case (rather than using one giant general model) – an Equinix report noted that in private deployments, “AI models can be smaller and faster… for specific use cases, consuming fewer resources”. On the other hand, cloud AI services offer convenience and cutting-edge models out-of-the-box. Organizations without extensive ML expertise can tap into state-of-the-art models (GPT-4, etc.) without worrying about the intricacies of training or fine-tuning. The trade-off is accepting the model largely as-is. In summary, Private AI enables extensive model customization and tuning (at the cost of requiring ML talent and effort), while cloud generative AI offers high-quality pretrained models with minimal effort but less flexibility to adapt them beyond what the provider supports.
Scalability & Elasticity: Technically, the cloud shines in elastic scaling – if workload increases, one can request more API capacity or spin up more instances (subject to cost), whereas on-premises capacity is fixed by the hardware in place. If an enterprise needs to handle unpredictable spikes in usage, cloud providers can “handle usage spikes gracefully” by dynamically allocating more resources. Achieving the same on-prem might require over-provisioning (buying extra GPUs to handle peak load that sits idle during normal times). Smaller organizations often prefer cloud AI initially for this reason – they can start small and scale up as needed without heavy investment. However, larger enterprises with steady high volumes might find it feasible to scale on-prem by adding servers, especially since on-prem costs do not scale linearly per use (once you own the hardware, using it more is essentially “free” until you saturate it, unlike per-call cloud fees). We will examine the cost implications of scaling in a later section. Technically, both private and public approaches can achieve the throughput and compute scale required for enterprise AI; the difference lies in how scaling is achieved (capital investment vs. on-demand rental) and the control vs convenience trade-off.
Regulatory Considerations (Data Sovereignty and Compliance)
One of the strongest drivers toward Private AI is regulatory compliance and data sovereignty requirements. In industries with strict data protection rules – healthcare (HIPAA), finance (GLBA, PCI), government, legal services, etc. – there are often legal barriers to sending sensitive data (patient records, financial transactions, legal documents) to an external cloud. Organizations must ensure that personal data stays within certain geographic boundaries or under certain controls (e.g. GDPR requires EU personal data to remain in EU-compliant environments). Using a public cloud generative AI service could raise concerns if the service is not fully compliant or could transfer data to servers in another jurisdiction. For example, feeding patient health information into a third-party AI API might violate HIPAA unless the service is specifically certified and a Business Associate Agreement is in place. Because of such concerns, “industries that require greater control over their data have been reticent to leverage public AI services due to security and privacy risks, cost concerns and vendor lock-in”. Instead, many firms in these sectors are exploring private AI infrastructure that allows them to use cutting-edge AI “without the risks and costs associated with public AI services”.
Data Sovereignty: Private AI enables data to be processed on-premises or in a specific controlled environment so that it never leaves the company’s domain. By “putting your AI infrastructure on-premises or in a secure colocation facility, you maintain complete control of your data”, meeting data localization and sovereignty requirements. For instance, a European bank can deploy a language model in its own EU data center to ensure all processing stays in-country, satisfying GDPR mandates. In contrast, using a US-based cloud AI could be problematic for sovereignty unless that provider guarantees EU-only data residency. Even then, some regulators and clients are more comfortable when the data never leaves the organization at all. Owning the entire stack means the company knows exactly where data is stored and processed, which is a huge advantage for compliance audits. As one enterprise AI architect put it, “with on-prem, you have total sovereignty over how data is stored, processed, and protected”.
Compliance and Auditability: Private AI can also make it easier to satisfy auditing and transparency requirements. Organizations can configure logging, monitoring, and access controls for the AI system to ensure they know exactly what data was used and how. Some regulations (and upcoming AI laws like the EU AI Act) may require demonstrating how an AI model makes decisions or ensuring that sensitive data isn’t inadvertently used to train a public model. If you use a cloud API, you often have to trust the vendor’s word on compliance and cannot inspect their backend. In a private deployment, you can enforce your own compliance policies. Notably, “less than half (44%) of organizations have well-defined policies regarding GenAI” today, indicating governance is lagging behind adoption. Running AI in-house can prompt organizations to develop clearer internal policies since they must manage the entire lifecycle themselves.
Regulatory Certifications: It’s worth mentioning that many cloud AI providers are working to meet compliance standards (for example, some offer HIPAA-compliant environments or EU regional instances). However, achieving certification for generative models is new territory. Companies with zero risk tolerance prefer not to rely on a third party’s certification alone. By keeping AI in a private environment, they avoid potential regulatory unknowns. Deloitte analysts note that legal and regulatory uncertainty around generative AI is slowing some enterprise deployments– until rules are clearer, firms err on the side of caution by containing AI usage internally. In summary, Private AI offers maximum data sovereignty and direct compliance control, which is especially critical in regulated sectors. It minimizes the legal risk of sensitive data exposure, whereas cloud-based AI requires careful vetting of the provider’s compliance measures and even then involves an element of trust. This compliance advantage is a primary reason many enterprises (banks, hospitals, governments) choose private over public AI solutions.
Economic Considerations (Total Cost of Ownership and Cost Structure)
Cost is a pivotal factor in the private vs cloud decision. At first glance, using a cloud AI service appears cheaper and faster to start – there’s no need to purchase expensive hardware or hire a large ML ops team; you pay only for what you use. Indeed, for initial pilots or low-volume use, cloud APIs have a “low barrier to entry”. However, as usage scales up, the economics can invert. Organizations are increasingly finding that running generative AI at scale via API can become very expensive, prompting a rethink of the cloud-first approach.
Pay-per-Use vs Upfront Investment: Cloud generative AI is typically billed per token (or character) processed, or per hour of model usage. These costs accumulate with every query. For example, using a large model like GPT-4 can cost fractions of a cent per token – trivial for one request, but significant when supporting hundreds of thousands of queries or processing long documents. Companies have been surprised by “sky-high cloud bills” once they move from small experiments to enterprise-scale deployments. By contrast, Private AI entails a high upfront cost: purchasing GPU servers, storage, and networking, plus installation and engineering. This capital expense can range from tens of thousands to millions of dollars depending on model size and user load. In exchange, the marginal cost of each query on an owned system is near zero (apart from power and maintenance). Thus, the breakeven point depends on usage volume:
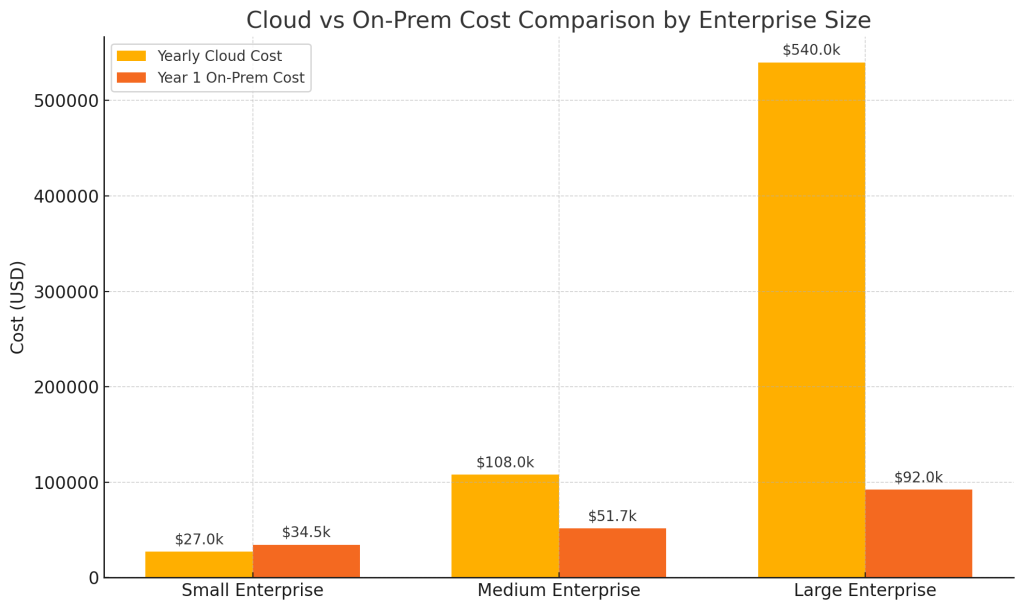
- Small-scale usage: Cloud is generally more cost-effective. One analysis found that for a small enterprise (~50 million tokens per month), running a model on-prem would cost about $35k in the first year vs $27k on the cloud – the cloud remains cheaper through year 1. Only by the end of year 2 would the on-prem investment pull ahead in cumulative cost. For modest or sporadic use cases, the subscription model avoids spending money on idle hardware.
- Medium-scale: As usage grows, on-prem becomes financially attractive sooner. With ~200M tokens/month (mid-sized company use), an on-prem setup was about half the cost of cloud in Year 1 ($52k vs $108k) and achieved ROI in ~6–7 months. The savings compound thereafter since Year 2 on-prem costs were minimal (only maintenance) against another $108k cloud bill.
- Large-scale: For heavy usage (billions of tokens), self-hosting is dramatically cheaper. A scenario of ~1B tokens/month (a large enterprise or popular consumer app) might incur $540k/year in cloud fees, whereas a one-time on-prem investment of ~$80k could handle it, reaching break-even in just 2 months. In such cases, “you could pay off an $80k system in 2 months of avoided cloud fees”. Over three years, studies show cloud costs can be 2–3× higher than on-prem for comparable AI workloads. One 3-year TCO analysis using the Llama-2 model found that AWS/Azure solutions would cost up to 2.88 times as much as a Dell on-premises deployment.
In summary, cloud AI is often cheaper for initial or low utilization, but Private AI can offer lower total cost of ownership (TCO) at scale. Enterprises with large, steady AI workloads often find it economical to invest in their own infrastructure. This is echoed by industry surveys: many companies are now repatriating AI workloads from cloud to on-prem to save on recurring costs.
Cost Predictability: Another economic benefit of Private AI is predictable costs. Cloud usage costs are variable and can spike if usage increases or models become more complex – prompting warnings that IT must “manage costs before costs manage them”. There is also the risk of “runaway” token costs – unexpected high bills if an application calls the AI more times or with more tokens than anticipated. On-prem costs, by contrast, are mostly upfront and fixed – once you’ve invested in hardware, you’re insulated from month-to-month cost swings. This budgeting certainty is appealing, as “no surprise cloud invoices” makes planning easier. A private deployment can also utilize existing assets (reusing on-prem servers or idle GPUs) to maximize ROI, whereas cloud spend is pure expense with no residual value.
Infrastructure vs Subscription Trade-off: It’s important to note that Private AI isn’t “free” after hardware purchase – there are ongoing operational expenses: electricity to power GPUs (which can be significant), cooling, hardware maintenance, and staff to manage the system. These operational costs must be factored in (often ~10-15% of hardware cost per year). Still, even including those, the cost curve tends to favor on-prem beyond a certain scale of usage. Cloud providers, of course, also charge a premium for the convenience and for handling all that on the backend. The key for decision-makers is to estimate their expected usage (number of queries, complexity of models, etc.) and perform a cost analysis over a multi-year period. Many have found that beyond the prototyping phase, the cloud’s pay-as-you-go model becomes more expensive in aggregate.
To illustrate, the table below (adapted from a practical cost comparison shows how usage level influences the break-even point for a 70B-parameter model deployment:
| Scenario | Approx. Monthly Usage | Yearly Cloud Cost | One-Time On-Prem Hardware | Breakeven Point |
| Small Enterprise | ~50 million tokens | ~$27k (API fees) | ~$30k (1× GPU server) + ~$4.5k/yr OpEx | ~End of Year 2 (cloud cheaper in year 1) |
| Medium Enterprise | ~200 million tokens | ~$108k/year | ~$45k (2× GPU servers) + ~$6.7k/yr OpEx | ~6–7 months (on-prem ROI within Year 1) |
| Large Enterprise | ~1 billion tokens | ~$540k/year | ~$80k (4× GPU servers) + ~$12k/yr OpEx | ~2 months (on-prem pays off almost immediately) |
Table: Illustrative cost comparison of cloud vs. on-prem for varying scales of generative AI usage. At low volumes, paying per use in the cloud is cost-effective, but at high volumes, owning infrastructure yields major savings.
Note: Actual costs vary with model size and provider pricing, but multiple analyses confirm the trend that beyond a threshold, on-prem can dramatically reduce the cost per inference.
Economic Trade-offs: While cost-saving is a big motivator for Private AI, it comes with trade-offs. The upfront capital requirement can be a barrier – not every organization can spend large sums on AI hardware, especially without guaranteed ROI. Cloud AI’s OPEX model is friendlier to cash flow and can be accounted for as a predictable operational expense. Additionally, cloud allows easy experimentation – teams can spin up a trial, spend a few hundred dollars on API calls, and shut it down, whereas experimenting on-prem requires already having the infrastructure in place (or investing in it). This is why many start in the cloud and only migrate once the use case and demand are proven. We also note that vendors are offering middle-ground options like “AI as a Service” on-prem (e.g. Dell APEX pay-per-use solutions) which give on-prem infrastructure with cloud-like billing. These can lower the entry barrier for private AI by spreading out costs.
In summary, cloud generative AI offers low startup cost and elastic pricing but can become unpredictably expensive at scale, while Private AI demands significant upfront investment but can yield lower long-term TCO and cost stability for heavy usage. Many enterprises are crunching the numbers: one firm observed that if you’re hitting even tens of millions of tokens per month, “a 70B on-prem solution could pay for itself surprisingly fast”. This financial calculus, coupled with regulatory and security factors, is driving a trend of moving AI workloads back in-house.
Security and Privacy Considerations
When it comes to security, the core question is: Do you trust an external provider with your sensitive data and AI models, or do you keep everything within your own secured environment? Private AI gives an organization complete control over security measures, whereas cloud-based AI means relying on the vendor’s security protocols and accepting some degree of exposure. Let’s break down the key security dimensions:
Data Privacy and Confidentiality: With Private AI, sensitive data (business documents, customer information, trade secrets, etc.) never leaves the organization’s boundaries. All processing happens either on-premises or in a self-managed private cloud. This drastically reduces the risk of data leakage to outsiders. Even the best cloud providers cannot fully eliminate the chance of a breach or misuse on their side – as one source noted, “even leading cloud vendors aren’t breach-proof”. By keeping data internal, companies remove third-party vectors from the equation. In a private deployment, access to data and the model can be tightly restricted to authorized internal personnel, and the data can reside on encrypted disks in a datacenter you control. In contrast, using a multi-tenant cloud service inherently involves sharing resources (and trust) with the provider and possibly other tenants. There’s a “multi-tenant risk” in public clouds – vulnerabilities or misconfigurations could potentially expose data between customers. Although such cross-tenant breaches are rare, they are not unheard of, and the mere possibility is unacceptable for some sensitive applications. Moreover, cloud AI providers typically log requests and may store submitted data (for example, OpenAI retains API inputs for a period unless you opt out). This means data you send could persist on their servers. Indeed, by default OpenAI “records and archives all conversations”, which led to concern that sensitive info might resurface in model outputs. High-profile incidents have highlighted this risk: for instance, Samsung had to ban employees from using ChatGPT after some inadvertently pasted confidential code into it, effectively leaking secrets to an external system. Such events underscore why many firms are forbidding public AI use and instead deploying “private ChatGPT” solutions where they can guarantee confidentiality.
Insider Threat and Shadow AI: Paradoxically, one security challenge with cloud AI is that it can turn internal users into inadvertent insider threats. The ease of access to tools like ChatGPT means employees might use them in unapproved ways (“shadow AI”), potentially disclosing sensitive data. A recent survey found “90% of organizations have users directly accessing GenAI apps like ChatGPT”, often without oversight. This expands the insider threat surface, as even well-meaning staff could input private data into external AI tools. With a sanctioned Private AI platform, employees have a safe alternative and are less tempted to use unsanctioned public services. By providing an internal AI assistant that is logged and governed, companies can mitigate the insider risk of data leakage. In a private setup, any misuse stays within the audit trail of the company and can be addressed via internal policy (much like any other IT system). Essentially, Private AI supports a “zero trust” posture – no data goes to third parties, eliminating the need to trust outsiders. Cloud AI can’t guarantee that level of isolation; you must trust the cloud provider with your data and also trust that your employees won’t misuse the external service. Many security officers feel more comfortable when “zero exposure” is ensured by keeping everything in-house.
Model Security and IP Protection: Security isn’t only about data – it’s also about the AI models themselves and any proprietary insights they contain. If a company fine-tunes a model on its sensitive data, that model now effectively embodies some of that knowledge. Hosting it privately prevents others from possibly accessing or interrogating it. If you were to send that data to a cloud provider for fine-tuning, there’s a question of who has access to the resulting model or if it could leak (unlikely, but a concern). Additionally, some organizations consider their usage patterns and prompts to be sensitive (e.g. what questions are executives asking the AI?). In a private deployment, all of that stays internal. With an API, you typically have to assume those patterns could be observed by the provider.
Another angle is robustness to external threats: A public-facing API might be targeted by hackers (e.g. trying to prompt it in malicious ways or find exploits in the model). Cloud AI providers invest heavily in securing their APIs, but as high-profile targets, they could face attacks. A privately hosted model, especially if kept completely off the public internet, presents a much smaller attack surface. It can be tucked away behind layers of corporate firewalls and zero-trust network architecture.
Isolation vs. Vendor Security Expertise: It should be noted that top cloud AI vendors have world-class security teams and often obtain certifications (ISO 27001, SOC 2, etc.), so using their service means inheriting those security measures. A small company’s on-prem deployment might not be as secure if they lack similar expertise. There is a trade-off between isolation and security resources. When you go private, you are responsible for securing the AI environment – securing servers, hardening the model against adversarial attacks, controlling access, etc. An insider with access could still abuse an on-prem model (for example, extracting data they shouldn’t from it). So internal governance is crucial. In fact, governance gaps are a major challenge – as noted earlier, many organizations have not yet implemented comprehensive GenAI usage policies. Whether using private or public AI, establishing strict guidelines and access controls is key. On-prem doesn’t automatically solve insider threats, but it limits the scope to internal actors.
In practice, many companies feel that having full control over the AI environment tilts the odds in their favor. They can enforce whatever security standards they want and are not exposed to multi-tenant risks or third-party breaches. Surveys show data security is a top reason for choosing private deployments – “the primary driver for private AI adoption is the need to protect sensitive data, especially for companies in heavily regulated sectors like healthcare and finance”, as one industry report highlights. By hosting AI “inside the company firewall”, firms can ensure compliance with internal security mandates. In summary, Private AI minimizes external security risks by keeping data and models under the company’s direct control, addressing many data privacy and insider threat concerns. Cloud AI requires trusting the provider’s security and mitigating new shadow IT risks, but benefits from the provider’s security expertise and infrastructure. The balance of risk vs. trust is a pivotal consideration in the private vs cloud decision.
Drivers for Private AI Adoption (Why Organizations Choose Private AI)
Considering the above dimensions, many enterprises are gravitating toward Private AI deployments to capitalize on several perceived (and actual) advantages over cloud-based models. Key drivers include:
- Data Privacy & Sovereignty: The foremost reason is to “protect sensitive data” and keep it within company-controlled boundaries. Private AI ensures customer data, intellectual property, or classified information isn’t handed to third parties. This is especially vital in finance, healthcare, government, and other regulated industries where data sovereignty is non-negotiable. By owning the AI stack, organizations avoid the risk of leaks or foreign access to their data and meet compliance requirements (HIPAA, GDPR, etc.) with greater ease.
- Compliance and Governance: Along with privacy, companies choose private deployments to adhere to strict compliance standards and audit requirements. They gain full visibility into how data is used and can implement custom governance frameworks. If a public AI service’s terms or practices don’t align with policy (e.g. retaining data for training), that’s a dealbreaker – hence a private solution is adopted to “ensure compliance with data regulations”. Owning the environment also simplifies demonstrating compliance to regulators, since nothing leaves the controlled environment.
- Control & Customization: Organizations want total control over their AI systems – from infrastructure to model behavior. By going on-prem, they can choose specific model architectures, fine-tune models with proprietary data, and optimize the system for their needs. This “strengthens your ability to manage, monitor and extend” the model. Many firms have unique domain knowledge (e.g. legal firms with vast case libraries, or manufacturers with technical manuals) that they can bake into a custom model when they have control. Private AI also avoids unexpected changes – for example, a cloud provider might update their model (to a new version that behaves differently) without the customer being ready. Some enterprises prefer to “decide when (and if) to upgrade the model” to maintain stability. This level of customization and change control is only possible when the model is in-house.
- Performance & Latency Advantages: As discussed, hosting models close to users/data can yield speed and latency benefits. Organizations that require real-time responses or have poor connectivity to cloud regions see a clear advantage in on-prem AI. Moreover, with private deployments, companies can ensure dedicated performance (no noisy neighbors in a shared environment). For certain high-throughput use cases (e.g. processing streams of sensor data), this dedicated performance is essential. Equinix noted that private AI allows using “smaller, faster models… that consume fewer resources” for targeted tasks, which can also improve performance and efficiency. In short, if low latency or guaranteed throughput is a must, private AI often wins out.
- Cost Efficiency at Scale: As detailed earlier, organizations anticipating heavy usage often project significant cost savings by investing in private infrastructure. While cloud costs can mushroom with usage, on-prem costs flatten out after the initial investment. An enterprise deploying many AI applications across departments found that relying solely on cloud APIs would “quickly become expensive”, including hefty data egress fees. In one case, a company saved $6.7M annually by moving its genAI workload on-prem after experiencing unsustainable cloud costs. Thus, lower total cost of ownership (in the long run) is a big motivator – especially for those who have already experienced bill shock from cloud AI. Private AI turns what would be an open-ended operational expense into a more predictable capital investment.
- Security & “Zero Trust” Posture: Many firms simply feel safer when they can isolate their AI within their own networks. As Pryon’s AI report put it, cloud solutions can’t guarantee “zero trust, zero exposure”, which “many enterprises now require”. The desire to eliminate external attack surfaces and third-party risk pushes organizations to self-host. They can enforce strict access controls, prevent unknown leakage, and address internal threats without also worrying about external vendors. This peace of mind around security is a strong perceived advantage of Private AI for risk-averse companies.
- Avoiding Vendor Lock-In: Relying on a cloud AI provider can create strategic dependencies. If the provider changes pricing, usage policies, or experiences outages, the customer is impacted. Several organizations fear being “locked in” to a single AI API or ecosystem. By contrast, running open-source or self-hosted models gives technical independence. As one expert noted, “cloud-native tools often come with proprietary formats… If your platform vendor changes pricing or APIs, you’re stuck. On-prem keeps you in control of your tech stack’s future”. Private AI adopters value this freedom to switch models or platforms on their own terms, without being tied to a specific cloud vendor. It also means they own the improvements they make (e.g., any fine-tuning done isn’t lost if they change solutions).
- Reliability and Continuity: In some cases, organizations have reliability concerns with cloud services (whether due to internet dependence or service stability). A private deployment, if managed well, can offer high availability on local networks even if the broader internet is down. For mission-critical applications in environments with limited connectivity (say, a ship at sea or a remote factory), an on-prem AI is the only viable choice. This is less about generative AI specifically and more a general driver for on-prem solutions – but it applies: e.g., a military application might require an AI system to run offline for security and reliability reasons.
In essence, companies choose Private AI to gain greater control, compliance, and potentially cost-savings, even if it means more responsibility. As one summary stated, it offers “the best of both worlds – the benefits of AI … while protecting proprietary data on secure, private infrastructure”. Of course, opting for private deployment is not the end of the story – organizations then face the challenge of successfully implementing and scaling these AI solutions internally, as discussed next.
Challenges in Scaling Generative AI in the Enterprise
Despite enthusiasm for generative AI’s potential, enterprises are learning that moving from pilot projects to wide-scale deployment is not trivial. A host of challenges can impede success. Below, we outline major challenges organizations face when scaling generative AI, and why having either private or public deployments doesn’t eliminate these concerns:
- Model Maintenance and Updates: Keeping AI models up-to-date and well-maintained is a non-trivial ongoing task. The field of AI is evolving rapidly – new model versions (e.g. GPT-4 → GPT-5, new open-source models) come out frequently. In a cloud scenario, the provider will update the model for you, but that can introduce changes you’re not ready for (or costs for accessing the latest model). In a private deployment, you have to track these advancements and decide when to upgrade or retrain models. This requires significant ML engineering effort. “On-prem means you decide when (and if) to upgrade the model – helpful for stability, but you must manually download, optimize, and test new releases.” Keeping a model updated with the latest knowledge (e.g. new data post original training cutoff) is another issue – many enterprises will need to periodically retrain or fine-tune models with fresh data, which is resource-intensive. Model maintenance also includes monitoring performance, fixing issues like model drift or bias, and patching any security vulnerabilities the model might have (yes, AI models can have bugs or behaviors that need fixing). If the internal team lacks a robust MLOps practice, these models can deteriorate or become outdated, reducing their usefulness over time. In essence, the operational workload of managing AI is a big challenge – Gartner often refers to this as the issue of “model management” that many companies underestimated during the excitement of initial deployment.
- Data Availability and Quality: Generative AI is only as good as the data it’s trained on and the data it’s provided for context. Enterprises often struggle with accessing high-quality, relevant data to fine-tune models or to feed into them for prompting. Many organizations are “challenged by the need to use high-quality data, because GenAI models require vast amounts of accurate, relevant data to be effective.” Data may be spread across silos, in inconsistent formats, or subject to privacy constraints. Also, creating training datasets (for fine-tuning or custom models) can be expensive and time-consuming – it might require labeling data or curating corpora from scratch. Data quality issues (typos, errors, biases in historical data) can lead to the AI producing poor outputs or perpetuating biases. Additionally, real-time data integration is a challenge: if you want the AI to be aware of the latest information (say, up-to-the-minute financial data or inventory levels), you need pipelines to feed that data to the model, which complicates the deployment. Data governance is critical – deciding what data the model can see and ensuring sensitive data is handled properly. Many firms have robust data management issues even before AI; introducing generative AI can expose those weaknesses. Successful scaling requires significant investment in data engineering and quality control to avoid garbage-in, garbage-out.
- Cost and Compute Resource Requirements: Generative AI, especially large language and vision models, are computationally intensive. Training a state-of-the-art model from scratch is often measured in millions of dollars in compute; even fine-tuning or running inference at scale demands powerful GPU or TPU hardware. Whether using cloud or on-prem, organizations face high costs for these resources. In the cloud, the cost challenge is managing API usage or renting dedicated GPU instances (which are expensive). On-prem, it’s the capital and operational cost of hardware and the electricity to run it (AI models can draw enormous power – data center power and cooling become limiting factors). A TechTarget review noted that GenAI workloads are driving up electricity usage in data centers, making energy availability and cost a concern. So even beyond purchasing hardware, companies must ensure their facilities (or cloud budgets) can handle the scale. Many CIOs have cited “managing costs” as a huge issue in generative AI projects. Without careful optimization, AI projects can quickly burn through funds – either via cloud bills or underutilized on-prem clusters. There’s also the challenge of scaling infrastructure in sync with project needs: If an AI initiative suddenly needs to ramp up (more users, bigger model), the organization must either allocate more cloud budget or procure and install more servers – both can introduce delays or require executive approval. Essentially, capacity planning and cost optimization are continuous challenges. Techniques like model compression, using smaller models, or sharing resources become important to make GenAI scaling affordable.
- Change Management and Talent Gap: Perhaps the most significant barrier is people and process, not technology. Many enterprises simply don’t yet have the AI talent and culture to fully harness generative AI. According to a CIO survey, “tech talent remains the No. 1 barrier to adoption” of generative AI. Building and operating GenAI systems demands a combination of data scientists, ML engineers, prompt engineers, and domain experts – a skill set that is in short supply in the market. Even hiring one “AI expert” isn’t enough; you need a multidisciplinary team and supporting roles (data engineers, MLOps, etc.). Upskilling existing staff is a huge task – e.g., training developers to understand prompt engineering or fine-tuning. In one study, 61% of respondents said users don’t know how to effectively capitalize on GenAI, and 51% reported a “lack of skilled employees with GenAI knowledge”. This talent gap can slow down projects or lead to suboptimal implementations. Additionally, change management is vital because GenAI can alter workflows and job roles. Employees might resist using AI or distrust its outputs, especially if they fear automation could replace jobs (the “workforce reshaping” challenge). Successful adoption requires executive champions, training programs, and often a cultural shift to become “AI-driven.” Some organizations are establishing AI Centers of Excellence to coordinate efforts, but not all have done so. Without proper change management, scaling a GenAI pilot to enterprise-wide usage can stall due to internal friction, lack of user buy-in, or simply failure to operationalize across departments. In summary, the human factor – both the scarcity of expert talent and the need to educate and align the broader workforce – is a significant hurdle in scaling generative AI.
- Governance, Risk, and Compliance: Deploying generative AI at scale introduces new risks that organizations must govern carefully. One challenge is dealing with the uncertainty of AI outputs – generative models can produce incorrect (“hallucinated”) information, biased content, or even confidential data from training (if not properly handled). Businesses need governance policies for how AI outputs are validated and used. For example, if an AI assistant drafts a document, who must review it? What is the protocol if the AI produces an offensive or inaccurate result? Many companies lack clear answers: less than half have comprehensive GenAI policies in place. This lack of governance can lead to mistakes or public relation issues. Another aspect is regulatory risk – laws around AI are evolving (e.g. the EU AI Act, FTC guidance in the US). Companies scaling GenAI must keep an eye on compliance with emerging regulations (for instance, handling of personal data, transparency requirements about AI-generated content, intellectual property rights for generated output, etc.). At the same time, they must manage ethical risks – ensuring the AI does not produce discriminatory or harmful content, and that any decisions made by AI that affect customers are fair and explainable. Many organizations are instituting AI governance committees or extending their risk management frameworks to include AI oversight. Without strong governance, the more AI is scaled, the greater the chance of something going wrong – e.g., an AI chatbot might inadvertently leak sensitive info, or an automated content generator might produce inappropriate material that harms the company’s reputation. Security risks were discussed earlier, but they remain a governance concern as well – IT and security leaders must enforce policies to prevent shadow AI or unsanctioned usage that could lead to data breaches. Finally, measuring and monitoring impact is a challenge: leadership will want to see ROI and ensure the AI is actually delivering value (and not just a shiny object). Many firms find that after initial hype, proving tangible business value from GenAI is difficult – only 15% of companies in one survey had a clear line of sight to financial benefits from GenAI so far. This can make it hard to justify further scaling unless governance and strategy focus the AI efforts on high-impact use cases.
In summary, scaling generative AI involves much more than choosing private or cloud deployment. Organizations must overcome operational, data, financial, talent, and governance challenges. Regardless of the deployment model, these issues determine whether AI initiatives truly succeed. Companies that address these challenges head-on – by investing in MLOps, data pipelines, upskilling talent, instituting strong governance, and aligning AI projects to business goals – will be in a better position to realize GenAI’s potential at scale. Those that don’t may find their AI pilots stall out or fail to deliver ROI, whether they ran them on-prem or in the cloud.
Conclusion
Both Private AI and cloud-based generative AI offer compelling benefits, and many enterprises will find that a hybrid approach serves them best. In fact, surveys indicate that most organizations plan to use a mix of on-premises and public cloud for GenAI solutions. For example, a company might use a private LLM for handling proprietary data and a cloud AI service for less sensitive tasks or specialized capabilities (like image generation), orchestrating between them as needed. Private AI deployments are being adopted to address data privacy, compliance, performance and cost concerns, while cloud AI is leveraged for its ease of use, scalability, and access to the latest models. As one Equinix report noted, private AI can deliver “the best of both worlds – allowing [organizations] to pursue all the benefits of AI… while protecting proprietary data on secure, private infrastructure”.
Looking forward, the landscape is likely to keep evolving. We may see cloud providers offer more “sovereign cloud” AI options (where the service runs in a dedicated isolated manner per customer or on customer-managed hardware), blurring the line between private and public. Tools for securely fine-tuning cloud models on private data (without the data ever leaving) are emerging as well. Conversely, on-prem model ecosystems (open-source models, etc.) are rapidly improving, narrowing the quality gap with the big proprietary models. This means enterprises will have more choices to mix and match. The decision framework will revolve around the dimensions discussed: technical needs, regulatory obligations, cost feasibility, and risk tolerance.
In conclusion, organizations should carefully evaluate use cases and requirements to decide where to deploy generative AI. Less sensitive or highly experimental use cases might start in the cloud for speed and flexibility. Mission-critical applications involving sensitive data or requiring heavy customization might justify the investment in Private AI. Many will follow a journey: prototype in the cloud, then scale on-premises once value is proven – a pattern already observed with a wave of companies repatriating AI workloads to control cost, performance, and compliance. What’s clear is that generative AI is here to stay (over 65% of organizations are already using it in some form), so enterprises must build a strategy that balances innovation with governance. By understanding the trade-offs between private and cloud deployments, businesses can maximize the benefits of generative AI while minimizing risks. The end goal is to responsibly harness GenAI for competitive advantage – whether that’s achieved with servers in one’s own data center, services from the cloud, or a combination of both.








.png)


