Scale GenAI apps
across
any hardware
Bud’s Production ready CPU Inferencing consumes 48.6% less power than GPU's.













Ready Stack
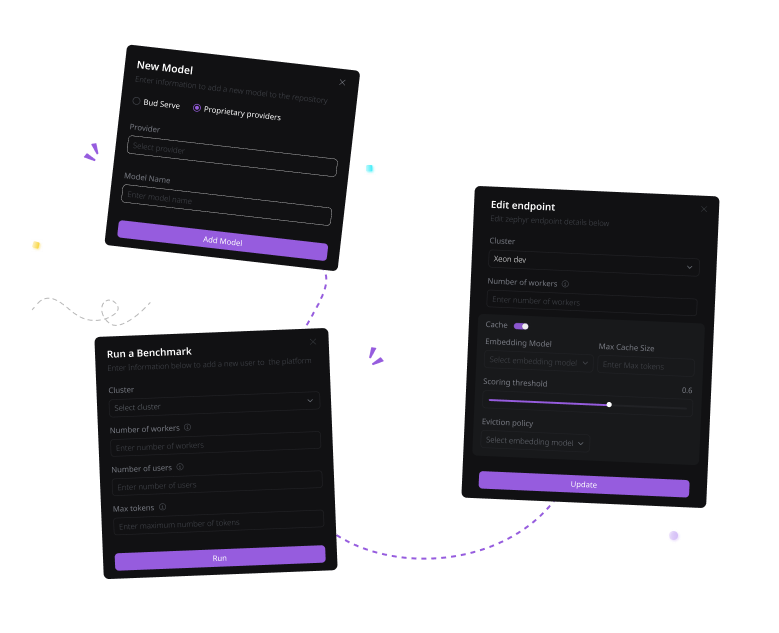
Streamline GenAI development with Bud’s serving stack that enables building portable, scalable and reliable applications across diverse platforms and architectures, all through a singular API for peak performance.
Whitepaper
Technology Use Cases such as RAG, Summarisation, and STT, showcasing how our SDKs empower a broad spectrum of AI applications.
Your Existing Infrastructure

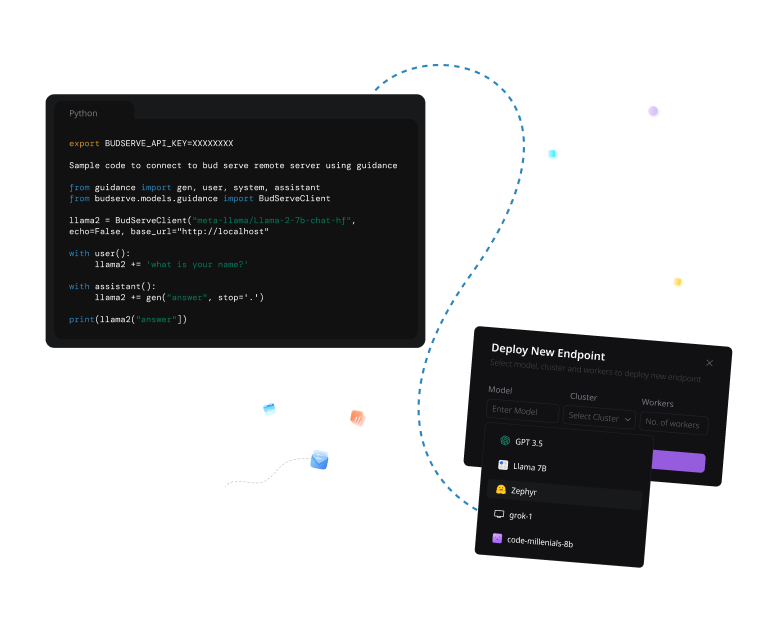
A single, unified set of APIs for building portable GenAI applications that can scale across various hardware architectures, platforms, clouds, clients, edge, and web environments, ensuring consistent and reliable performance in all deployments.

For the first time, Bud Runtime has made CPU inference throughput, latency, and scalability comparable to NVIDIA GPUs. Additionally, Bud Runtime delivers state-of-the-art performance across various hardware types, including HPUs, AMD ROCm, and AMD/Arm CPUs.

Current GPU systems often underutilize CPUs and RAM after model loading. Bud Runtime takes advantage of this unused infrastructure to boost throughput by 60-70%. It enables the scaling of GenAI applications across various hardware and operating systems within the same cluster, allowing for seamless operation on NVIDIA, Intel, and AMD devices simultaneously.







Using Bud Runtime on CPUs with accelerators
Compared to LLaMa CPP on RTX 4790 & CPU
All experiments with LaMa 2 7B
[Uses a LLaMa-2 7B with FP16 on GPUs & BF16 on CPUs, without using optimisations that require fine tuning or pruning like Medusa, Eagle, speculative decoding]
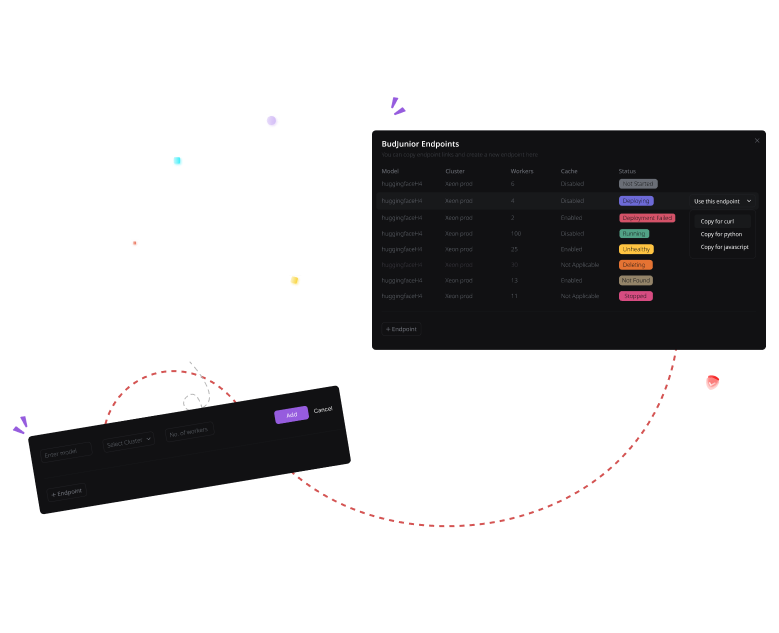
Bud Runtime is a Generative AI serving and inference optimization software stack that delivers state-of-the-art performance across any hardware and OS. It ensures production-ready deployments on CPUs, HPUs, NPUs, and GPUs.
GenAI Made Practical, Profitable and Scalable!




Runtime Inference Engine
Models
Case studies
Research & Thoughts
Blogs
News and Updates
© 2024, Bud Ecosystem Inc. All right reserved.