


In recent years, Generative Large Language Models have become a centerpiece in the domain of NLP, catching the attention of researchers and non-researchers alike for their impressive capabilities. Their ability to capture context and generate human-like text has revolutionized the way we interact with machines, and opened up creative possibilities for applications in various domains, such as customer service, content creation, and numerous others.
The success of LLMs can be largely attributed to their advanced architectures, extensive training on vast datasets and alignment strategies. These elements enable them to capture complex patterns and nuances in everyday human language, allowing them to generate detailed, sophisticated text that aligns well with human expectations and the task at hand. For many in the latter half of the 20th century, these concepts seemed like a distant dream, especially as the true nature of how computers work became apparent. Yet here we are!
However, with great power comes greater costs. The deployment of LLMs in production environments can quickly become a costly affair. The sheer size of these models, coupled with the computational resources required for inference, can quickly escalate operational expenses, making it challenging for organizations to scale their NLP applications. This has led to a growing interest in developing cost-effective strategies for deploying LLMs in real-world scenarios, without compromising on performance or quality. In this article, we’ll explore the challenges associated with deploying LLMs and discuss some potential solutions that aim to bridge the gap between cost and performance.
The Good Ol’ APIs
Now, you might be thinking, “Why not just use an inference endpoint API?”
After all, who wants to deal with the hassle of setting up and maintaining their own GPU clusters for LLM inference? And you’d be right— many cloud providers offer LLM inference APIs that allow users to access these models without the need for expensive hardware or infrastructure. This convenience offered by inference APIs is a major draw for users, as it eliminates the need to invest in specialized hardware or manage complex computing environments, by leveraging the provider’s own infrastructure, which can handle the computational load required for LLM inference. This way, users can access the models via simple HTTP requests, making it easy to integrate them into their applications. But there’s a catch. While APIs are a convenient option for many users, they come with their own set of basic challenges.
- For new startups, the costs can quickly add up, especially when using proprietary inference APIs such as OpenAI & Anthropic. Moreover, there really isn’t much variety of such ready-to-serve APIs in the market that can foster a price competition dynamic. This leads to a monopoly of sorts, where the users are forced to pay a premium for the endpoint service.
- API usage can be subject to token level rate limits, which can impact the scalability of applications that rely heavily on LLMs. OpenAI’s API, for example, is heavily rate limited across 5 measures: RPM (requests per minute), RPD (requests per day), RPM (requests per month), TPM (tokens per minute) & IPM (images per minute). This can be a significant limitation for applications that require real-time responses or handle large volumes of text-to-image generation.
- Billing policies can be complex and vary between providers, making it difficult to predict costs accurately. Different providers impose different constraints. For example, some providers charge based on the number of tokens processed, while others charge based on the number of requests made. This can make it challenging for users to estimate their monthly costs and budget accordingly.
- Data privacy and security concerns can also be a major issue with API-based deployments, as sensitive data may need to be transmitted to the provider’s servers for processing. For organizations that handle proprietary, personal or just any confidential information, this can be a significant barrier to adoption.
- APIs enforce strict TOS & Usage policies that can limit the flexibility of applications that rely on LLMs. For example, OpenAI’s API has a strict policy on the use of their models for generating training datasets to create models that compete with their own offerings, unless it’s strictly for non-commercial research purposes.
- Downtime or service interruptions on the provider’s end can disrupt the functioning of entire supply chain of applications that depend on real-time responses from the model.
- Lastly, there’s really isn’t much variety in the models that are available for inference via APIs. Most providers offer a limited selection of models, which may not always meet the specific needs of users. This can be a significant limitation for organizations that require specialized finetuned models for their applications.
A Rough Cost Estimate of Using OpenAI’s completions API 💵
For a rough estimate, OpenAI bills $2.50 per million input tokens and $10 per million output tokens for their latest flagship model, GPT-4o. For a simple chatbot based on 4o, with a modest sliding context window of 8192 tokens, generating 1000 tokens per response (e.g. code generation) and making about 400,000 API calls each month, the monthly bill would equate to roughly around $12000. For Claude 3.5 Sonnet, the bill would equate around $15000 per month. For RAG based applications, these costs could be even higher. This can quickly add up for organizations that require large-scale deployments of LLMs.
SLMs: The Affordable Workhorses
LLMs are born in private datacenters, often as a part of bleeding-edge research to serve as a stepping stone in the development of artificial general intelligence (AGI) that may take their place in the future. While they garner much of the spotlight in the present NLP research and startup communities for their crazy zero-shot skills and potential commercial applications, there’s another class of models that often gets overlooked in this craze: Small Language Models (SLMs). SLMs are designed with the vision of democratizing access to NLP technologies and making them available to the general masses, and they are slowly but surely gaining traction in the industry.
SLMs are, with fewer parameters and lower computational requirements, products of research efforts to optimize over existing architectures, this is primarily due to the fact that SLMs are easier to train compared to LLMs, require less training data, and are more costeffective to deploy. This makes them perfect candidates for experimental studies, rapid prototyping, and even production use cases where the task at hand is relatively simple and doesn’t require the full firepower of an LLM, such as a virtual customer support agents, or a text summarization service, or even a text based RPG.
How ‘Small’ is ‘Small’? 🤏
It is important to know that ‘Small’ is a relative term here, as even SLMs can scale across billions of parameters and require significant computational resources during inference. Personally, I categorize SLMs as models with up to 10 billion parameters—a definition that has served me well in various discussions with my colleagues. However, this isn’t a rigid classification; it can shift depending on the context. For example, a 1 billion parameter model might seem small compared to a colossal 1.8 trillion parameter multimodal mixture of experts like GPT-4o (speculated, but mouthful). Yet, even a hefty 100 billion parameter model can be dwarfed in such comparisons!
The Reason Behind the Performance Gap
Let us motivate the discussion with a simple question:
Does model size really matter?
Yes and no. While it has been proven that larger language models (LLMs) have an advantage over smaller language models (SLMs) in terms of performance, accuracy, and generalization, there are a number of nuances to consider. The performance gap between LLMs and SLMs isn’t just about the number of parameters in the model; it’s also about the quality of the training data, the training process, the model architecture, and the alignment strategies used during training. In other words, it’s not just about the size of the model, but also about how well it has been trained and also the nature of its dataset.
But saying this would only be a scratch at the surface, wouldn’t it? So let’s dive deep.
The Culprit: Transformer Scaling Laws
The reason for this is actually due to something called the ‘Transformer scaling laws’. But before presenting the long answer, let us take a look at a line from the paper titled, Scaling Laws for Neural Language Models (Kaplan et. al, 2020)
“Model performance depends most strongly on scale, which consists of three factors: the number of model parameters N (excluding embeddings), the size of the dataset D, and the amount of compute C used for training.”
Neural scaling laws capture a model’s performance (often measured by its test loss L or some accuracy metric) as a function of certain factors like the number of parameters in the model N, the size of the training dataset D, and the amount of compute used during training C. In other words,
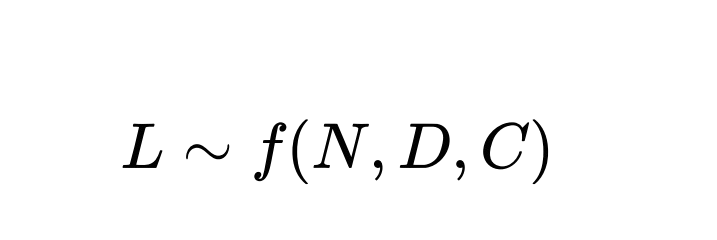
More specifically, they describe an empirical functional relationship that has been consistently observed with dense neural networks.
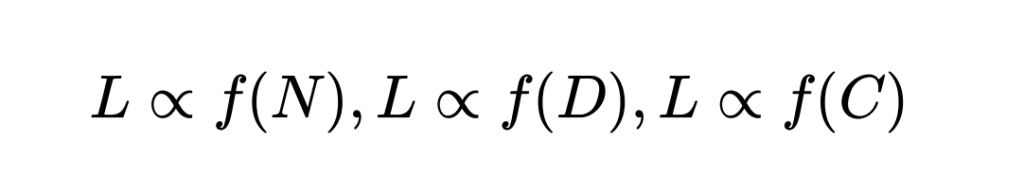
These influences could be modeled as simple statistical power-law relationships of the form
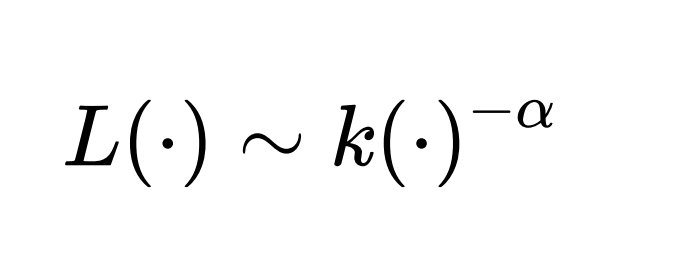
Which is essentially, a decreasing function which models how the test loss L decreases as each factor is adjusted. Thus, we have the following relationships:

Where A, B and Cmin are proportionality constants for each factor, that depend on the specific training setup and α, β and γ are the scaling exponents that determine the rate at which the loss decreases with respect to each factor. The steepness of the graph depends on the value of these scaling factors.
We are particularly interested in finding the values of α, β and γ for transformers, as they can provide insights into how their performance scales with respect to the number of parameters, the size of the training dataset, and the amount of compute used during training.
A 2020 ArXiv entry by OpenAI, titled Scaling Laws for Neural Language Models (Kaplan et. al) provides some insight into this. In summary, they found out by training a large number of transformers that for a given compute budget C, the β scaling exponent for the dataset size D was observed to be close to 0.27, whereas the α scaling exponent for the number of parameters N was observed close to 0.73. This means that the loss decreases at a slower rate with respect to the size of the training dataset compared to the number of parameters in the model. In other words, increasing the number of parameters in a model seemed to have a greater positive impact on its performance than increasing the size of the training dataset.
In the words of the authors: “Our results strongly suggest that larger models will continue to perform better, and will also be much more sample efficient than has been previously appreciated. Big models may be more important than big data.“
Info
Kaplan’s paper posited that language models become ‘sample efficient’ as number of parameters scales up i.e., able to capture more context from less data
This premature conclusion (as we will see later on) only lead to a goose chase race for developing the biggest, baddest and meanest LLMs scaling across trillions of parameters, starting with Nvidia’s Megatron-Turing NLG 530B, BAAI’s Wu Dao 1.75T, HuggingFace’s BLOOM 175B and Google’s PaLM 540B.
The moment of reckoning
The reality check came in 2 years later from Google DeepMind’s paper titled ‘Training Compute-Optimal Large Language Models (Hoffman et. al, 2022) which, based on their own experimentations with 400 LLMs varying in N and D, revised both α and β factors to 0.5, indicating that the loss decreases at the same rate with respect to the number of parameters and dataset size. This was in stark contrast to the previous findings from OpenAI, and it suggested that the size of the training dataset was just as important as the number of parameters in the model for achieving optimal performance.
Based on these results, DeepMind went on to train ‘Chinchilla’, a 70 billion parameter ‘toy’ model under a data-heavy setting with a 20 : 1 token to parameter ratio. Chinchilla outperformed models 4 times its size on several benchmarks, including GPT-3, indicating that training on a larger dataset can significantly improve the performance of language models, even with fewer parameters.
Vanishing Hype
Poof! Suddenly all the hype around trillion parameter models seemed to be just that – hype! Most pre-existing models were found to be severely undertrained & data deficient for their size, and the research focus shifted now towards curating better, larger datasets instead of just plainly scaling up the model size. The conclusions of this study gave paved way for the development of newer architectures such as LLaMa and Gemma as we know them today.
…but it didn’t stop there
A new trend emerged following the results of DeepMind’s Chinchilla paper: “Overtraining”
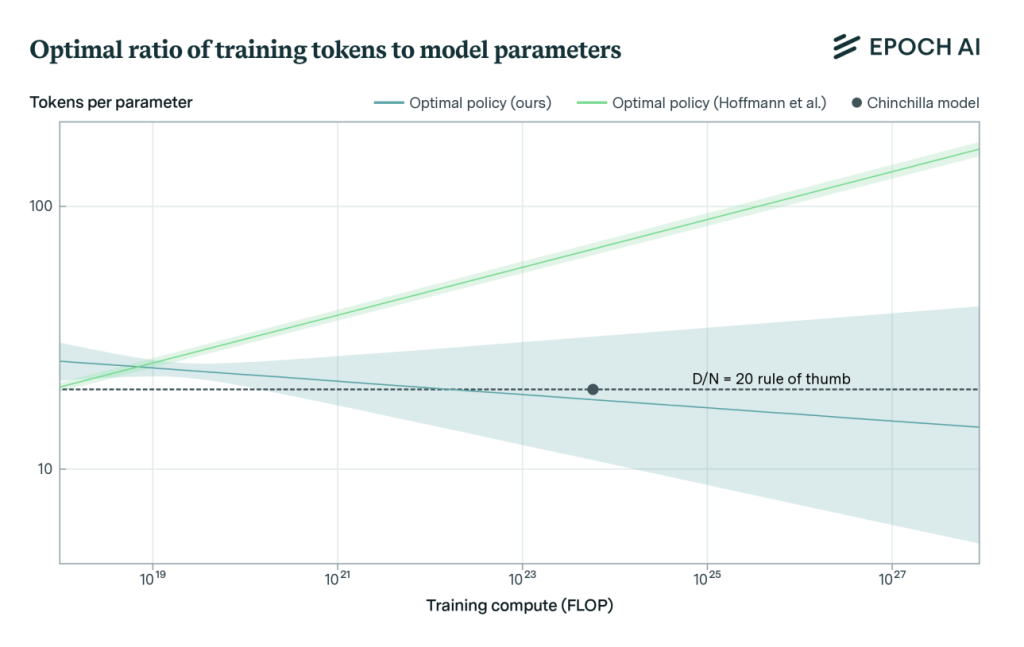
This approach involves training models on significantly more training tokens than the Chinchilla scaling laws had previously established (20 : 1), sometimes even for multiple epochs over the same dataset until the loss began appearing to plateau. The idea is to push the limits of the models and see how much they could learn from the training data. A prime example of this has been the evolution of Meta’s LLaMa series of language models. Llama 1 followed the Chinchilla TPP ratio of 20:1, Llama 2 took this to a slightly higher 28:1, and Llama 3.X finally notched this all the way up to 215:1.
Heck! Databricks even tried experimenting with a TPP ratio of 10,000:1! Even with this, transformers show no signs of convergence.
Quoting from Beyond Chinchila Paper:
“Our key finding is that loss continues to decrease as we increase tokens per parameter, even to extreme ratios. Although it takes exponentially more tokens to reduce loss at large ratios, loss does not plateau as we scale to 10,000 tokens per parameter for our 150M model. For models larger than 150M, we only test up to a maximum of 1,000 tokens per parameter due to resource constraints, and at this scale we also see no evidence of loss flat-lining. Further experiments are needed to see how loss scales beyond this point.”
Extending the discussion to the LLM vs SLM debate
The key takeaway from transformer scaling laws is a paradigm that language models store captured patterns and relationships from the training data inside their parametric memory. The higher the number of parameters N in a model, the more parametric memory is available for the model to store these patterns.
We can think of patterns appearing in the training data in the form of phrases, idioms, grammatical structures, and so on, which the model learns. For example, articles ‘a’, ‘an’, ‘the’ are often followed by nouns. Since such patterns that appear almost everywhere in the training data. The probability of these patterns occurring is high. In terms of information theory, these patterns have low self-information content (i.e. has a low surprisal value), as they are predictable and occur frequently in the data. During training, when a model passes over the training data multiple times, it captures these generally occurring patterns and stores them in its available parametric memory as initial weight updates.
However, there are some patterns that are more nuanced. For example, the phrase ‘the cat sat on the mat’ is a common phrase in English, but it is not as common as ‘the cat tips his fedora’. The latter phrase has a relatively higher self-information content (i.e. a higher surprisal value) because it is less predictable and occurs less frequently in the dataset.
Another example would be from math, where a Hesse matrix is defined more commonly as the second partial derivative of a scalar valued, multivariable function and less commonly as the Jacobian of the gradient transposed of such a function. The latter definition has a higher self-information content than the former, as it is less predictable and occurs less frequently in the data. Models take more time to ingest such complex patterns.
Storing complex patterns (structures and relationships) with higher self information content (often measured in bits or nats) also requires more parametric memory. The more parametric memory a model has access to, the more patterns (complex or simple) it can capture and store within its layers. This is why larger models tend to have an advantage over smaller models, by the virtue of having the capacity to store more patterns and relationships from the training data.
…but now, let us consider a particularly data deficient training scenario
Larger datasets have the potential to contain more complex patterns and relationships than smaller datasets. They can provide a richer source of relationships for the model to sift through and learn from. But when the training dataset is small, it may not contain sufficient enough examples for the model to learn effectively. For each pass over such training data, the model repeatedly captures the same old limited set of patterns & relationships, eventually overfitting on the training split and leading to poor generalization. This is why most pre-Chinchilla era models were found to be undertrained and data deficient for their size.
Is Convergence a Myth & Data still King?
We observed from the Chinchilla era findings that training on larger datasets can significantly enhance the performance of language models of a given size , even when the models have fewer parameters. Post-Chinchilla era observations indicate that the loss continues to decrease as we increase the number of tokens per parameter, even to extreme ratios, supporting this argument. Although it requires exponentially more tokens to achieve a reduction in loss at these extreme ratios, the loss does not plateau even when scaling to 10,000 tokens per parameter. This suggests that there is still much to be learned from the training data and that transformers do not reach a hard limit on convergence.
Small language models, by the virtue of having less parametric memory, may struggle to capture complex linguistic patterns in the training dataset, particularly those with high self-information content (surprisal value) in a single pass. This doesn’t mean SLMs are weak learners incapable of learning complex patterns, but rather that they may need more passes over the training data to observe them properly, or require better organized training datasets that make such complicated patterns more apparent (by artificially increasing the signal-tonoise ratio, including more diversity and complexity in the data, etc.). This is where the size and quality of the training dataset D plays an extremely crucial role in the performance of SLMs.
There are a number of ways this can be done, such as:
- By using more organized training datasets that have a consistent writing style & diversity of topics, as shown in the Microsoft Phi/’Textbooks Are All You Need’ paper (Gunasekar et. al., 2023).
- By using synthetic data augmentation techniques that can increase the diversity, & complexity of the training dataset, as shown in the WizardLM paper (Xu et. al., 2023)
- By employing LLMs & SLMs in a teacher-student setup where the SLM learns to predict the teacher’s output distribution, as shown in the DistilBERT paper (Sanh et. al., 2019).
The moral of the story
In this article, we have now reached a point where we are sufficiently equipped to dismiss the claim that SLMs are toy models in the realm of NLP. The major reason: For one, the performance gap between LLMs and SLMs is now not as wide as it used to be initially. Recent advancements following post-Chinchilla scaling in model architectures, distillation based training techniques, and improved parameter efficient fine-tuning strategies have significantly improved the performance of SLMs, making them more competitive with their larger counterparts.
For example, Meta’s recent release of Llama 3.3 70B Instruct, a 70 billion parameter SLM, has demonstrated equivalent performance to their previous Llama 3.1 405B Instruct, which is a 405 billion parameter LLM, on a wide range of LLM benchmarks. It would be an understatement to say that SLMs are now capable of achieving impressive results across general purpose tasks, even in the absence of the vast parametric memory that LLMs possess.
Even for specialized tasks, SLMs have shown remarkable performance. For instance, Qwen 2.5 Coder 32B, a mere 32 billion parameter SLM, has consistently outperformed OpenAI’s flagship GPT-4o on several code generation & math benchmarks. This is a significant development, as it indicates that SLMs can be viable alternatives to LLMs for task specific use cases, especially when cost considerations are taken into account. This makes them potentially useful as virtual customer support agents, AI tutors, RAG chatbots, Document summarizers and so on.
So the final question is:
How much parametric memory does a model your use case really need?
At this point, I can’t stress enough the importance of understanding the specific requirements of your use case before deciding on the model architecture. It’s sad to see that many organizations often fall into the trap of blindly choosing the largest, latest model available, without considering whether it’s truly necessary for their application. Moreover, it is much sadder to see how GPU cycles are wasted on models that are simply too large for the task at hand. GPUs are very expensive to operate, consume a lot of electricity, and are notorious for their high heat & carbon footprint.
Of all animals, humans have an innate, primal tendency to be attracted towards the biggest, shiniest, most powerful thing in the room, but in the realm of AI, it is important to remember that bigger isn’t always better. Especially for business applications, where efficiency, cost effectiveness, and performance are key factors in determining the success of an AI deployment. So it’s a no-brainer that choosing the right model size is crucial for achieving the right balance between cost and performance, as doing otherwise can lead to unnecessary costs, longer inference times, and even suboptimal performance in some cases (more on this in my next article post).
While LLMs are undoubtedly powerful and versatile, they may not always be the best choice for every application given the associated costs. Post-Chinchilla developments in recent years, give enough reason to support their usage. For example, if you’re building a simple chatbot that responds to customer queries, a high performance, state of the art SLM might be more than what’s sufficient to handle most customer queries, without the need for a large, expensive LLM. This way, you can save on operational costs, reduce latency, and still provide a high-quality experience to your users. On the other hand, if you’re building a complex multi-turn conversational AI agent that acts as an AI tutor for grade schoolers and college students, a large LLM might be more suitable, as it can better handle the nuanced context and generate more STEM accurate responses without much in-context instructions. In this case, the higher performance of the LLM would actually justify the additional costs associated with its deployment.
Signing off
Whoa that was a big one! We looked at the evolution of language models, how they have revolutionized the way we interact with machines, we discussed some philosophies behind their research, the kind of novel challenges they bring. We looked at how SLMs are gaining traction as promising cost-effective alternatives to their elder siblings, the LLMs. The discussion on transformer scaling laws, the Chinchilla era and newer paradigms has underscored the importance of both model size and data quality in achieving optimal performance. We’ve seen how recent advancements have narrowed the performance gap between LLMs and SLMs, making the latter a compelling choice for many applications. Ultimately, the key takeaway is the importance of aligning model choice with specific use case requirements. Bigger isn’t always better; understanding the balance between cost, performance, and application needs is crucial for successful AI deployment.

Too much to digest? Don’t worry, I’ll be back.
In the next article, we’ll look at a peculiar problem, not just any problem, but a conundrum 🥁that many organizations face when they’re still indecisive about which model to choose, and how you can leverage something called a dynamic language model router to automate such choices for you!
Until then, stay abuzz!








.png)


