


As artificial intelligence (AI) becomes an integral part of business operations, companies are increasingly leveraging powerful language models to create innovative products. Third-party LLM services, such as OpenAI’s GPT-4 and Claude, have become go-to solutions for many businesses, particularly for pilot projects and proof-of-concept initiatives. Their ease of use and fast implementation make them attractive options for companies just starting to explore AI capabilities. However, as organizations scale and transition to production, many realize that relying on LLM services can become prohibitively expensive and difficult to manage effectively.
In a recent study, several key limitations of proprietary LLM services have come to light. These include issues around cost, performance reliability, latency variability, and unpredictable uptime. As a result, businesses are seeking more sustainable alternatives, and one solution gaining traction is the use of open-source small language models (SLMs). In this post, we explore why SLMs are emerging as a compelling alternative to large-scale models like GPT-4 and how they address many of the challenges companies face when scaling AI in production environments.
The Challenges with Thirdparty LLM Services
Third-party LLM services come with significant drawbacks that make them less suitable for large-scale, production-oriented use cases. For example, a study on the effectiveness of OpenAI’s GPT-4 service pointed out the following challenges;
- Cost: OpenAI’s pricing structure can quickly become prohibitively expensive, especially as traffic increases. As of December 2023, the cost for 1,000 input tokens is $0.03, and for output tokens, it’s $0.06. This means that each request could cost upwards of $0.09, with higher costs for more complex queries. For a system receiving 1,000 requests per day, the monthly cost could reach $2,700, and if traffic scales to 360,000 requests per day, the cost could exceed $1,000,000 per month. For many companies, especially startups, these costs are simply unsustainable.
- Latency and Performance Variability: Many developers report inconsistent performance with OpenAI’s APIs, with latency fluctuating from less than one second to several minutes. Additionally, frequent outages have plagued the service, impacting reliability in production environments. For businesses relying on real-time AI interactions, such unpredictability can pose serious risks.
- Token Limits: OpenAI imposes strict token limits per minute, which can disrupt production systems if exceeded. In some cases, this results in dropped requests and increased response latency as the system retries.
Are Small Language Models a Viable Alternative?
To address these challenges, small language models (SLMs) have gained attention as a more cost-effective and reliable alternative to proprietary LLMs. Unlike GPT-4, which requires cloud-based API calls, SLMs can be self-hosted, offering businesses greater control over performance and costs.
Key Advantages of SLMs Over LLMs
- Cost Savings: Studies have shown that SLMs can be significantly more affordable than large-scale models like GPT-4. Depending on the model, self-hosted SLMs can reduce costs by 5x to 29x. This represents a major shift, particularly for businesses with tight budgets or large-scale operations.
- Performance and Latency: While OpenAI’s GPT-4 offers excellent performance, its latency can be highly variable, and its performance can fluctuate throughout the day. In contrast, SLMs exhibit more consistent latency and performance, particularly when self-hosted. For instance, several SLMs, including Mistral-7B and Orca-mini-3B, are able to generate responses within a second, making them competitive in terms of speed and efficiency.
- Reliability: Self-hosting SLMs offer a major advantage in terms of reducing variability. OpenAI’s API, for instance, has been observed to experience significant latency spikes during different times of the day, with delays ranging from 3.4 seconds to 8.6 seconds. In comparison, self-hosted SLMs exhibit much less variability in response times, making them a more stable choice for businesses that require predictable performance.
- Response Quality: While GPT-4 is known for its high-quality output, studies have shown that several SLMs come close to matching or even exceeding its performance in specific tasks. For example, models like Vicuna-7B and Starling-lm-7B generate responses that are nearly indistinguishable from GPT-4’s in terms of quality. Even more encouraging is the fact that quantized versions of these models—smaller, optimized versions—can maintain similar performance at a fraction of the cost.
Case Study: SLMs in Action
A case study conducted by researchers explored the possibility of replacing OpenAI’s GPT-4 with self-hosted SLMs in a production setting. The application in question was a daily “pep talk” feature that generated personalized motivational messages for users based on their past behavior and upcoming tasks. The study compared several SLMs to OpenAI’s GPT-4 in terms of response quality, latency, reliability, and cost-effectiveness.
Quality
The SLMs evaluated, including Starling-lm:7B and Vicuna:7B, produced responses with quality comparable to GPT-4. Even quantized versions of these models, which are smaller in size, managed to generate high-quality text with impressive consistency.
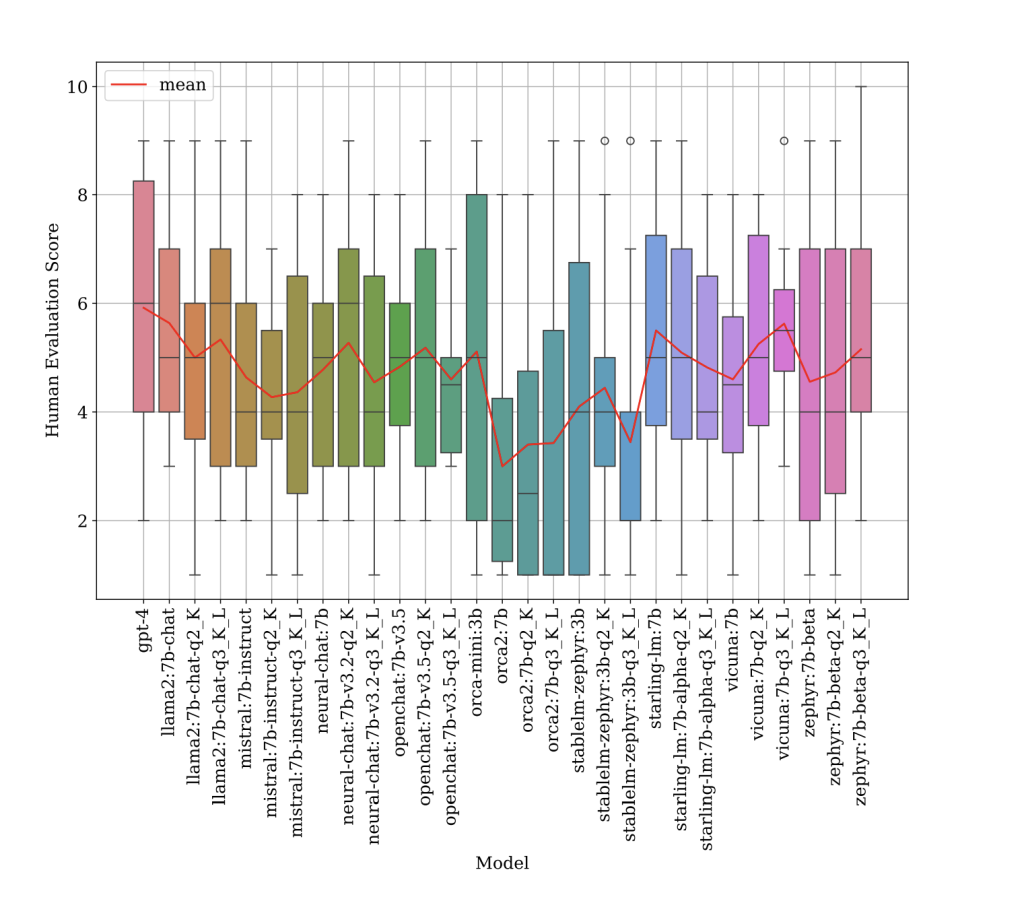
The figure above shows the response quality of GPT-4 and SLMs, as rated by human reviewers. Score distribution (boxes) and mean score (line) of each model are shown. The mean scores of SLMs evaluated, including Starling-lm:7B and Vicuna:7B, produced responses with quality comparable to GPT-4.
Latency
On average, the latency of the top-performing SLMs was on par with GPT-4, with some models even outperforming GPT-4 in per-token generation speed.
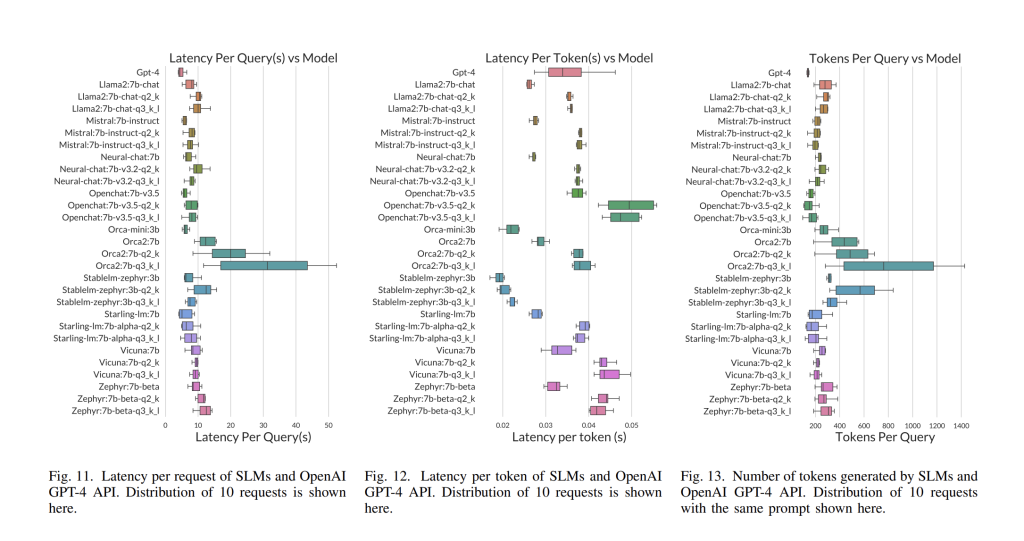
The figure above shows the latency of different models that were evaluated. While GPT4 (1st row) has the lowest per-request latency, most SLMs provide competitive latency performance. Specifically, the mean request latency of mistral:7b-instruct, orca-mini:3b and stablelm-zephyr:3b are within <1 second of GPT-4’s latency. Moreover, it is observed that GPT-4’s response length has a much lower variance than the SLMs, indicating its responses more consistently follow the prompt’s instructions. Furthermore, Figure 12 shows that many SLMs, such as StableLM-zephyr-3b, mistral-7b, and starlingLM, are faster at generating tokens than OpenAI GPT4.
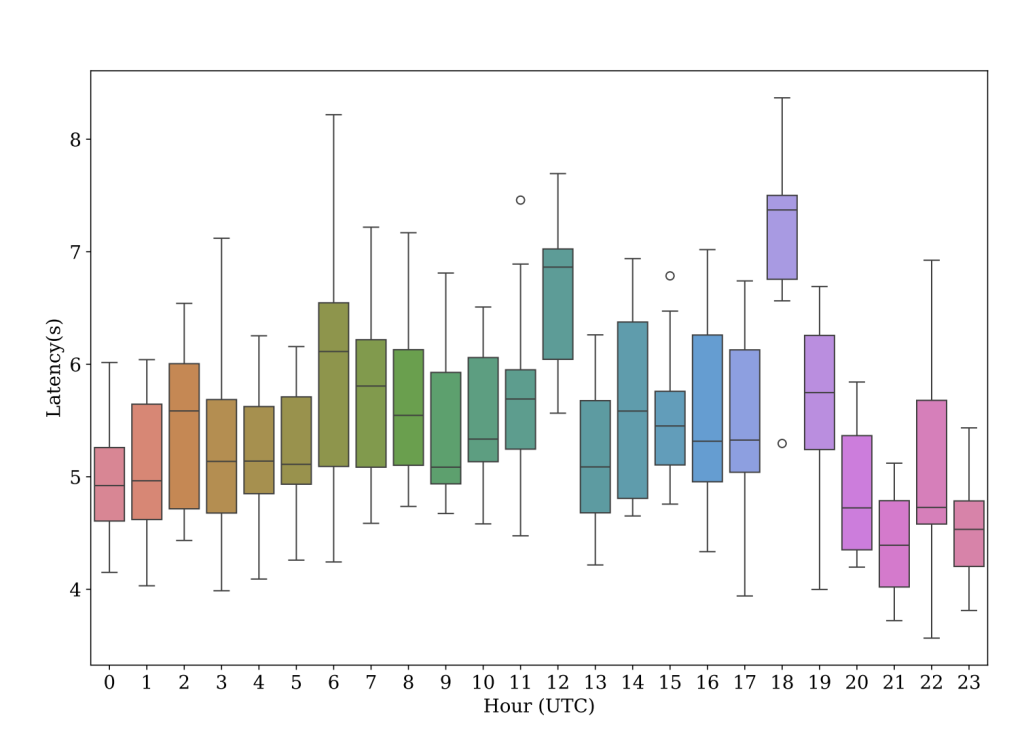
The experiments also showed significant variations in request latency for OpenAI at different times of the day, where perrequest latency ranges from 3.4 seconds to 8.6 seconds. This large variability presents a significant challenge in production settings, where predictability is crucial. The experiment results indicates that self-hosted SLMs have a significantly more consistent request latency over the course of the 24 hours and a narrower request-to-request distribution within the same hour
Cost
The cost savings were striking. The researchers found that the total cost of self-hosting SLMs ranged from 5 to 29 times lower than the cost of using OpenAI’s GPT-4 API. This reduction in operational expenses makes SLMs an attractive choice for businesses seeking to scale AI applications without breaking the bank.
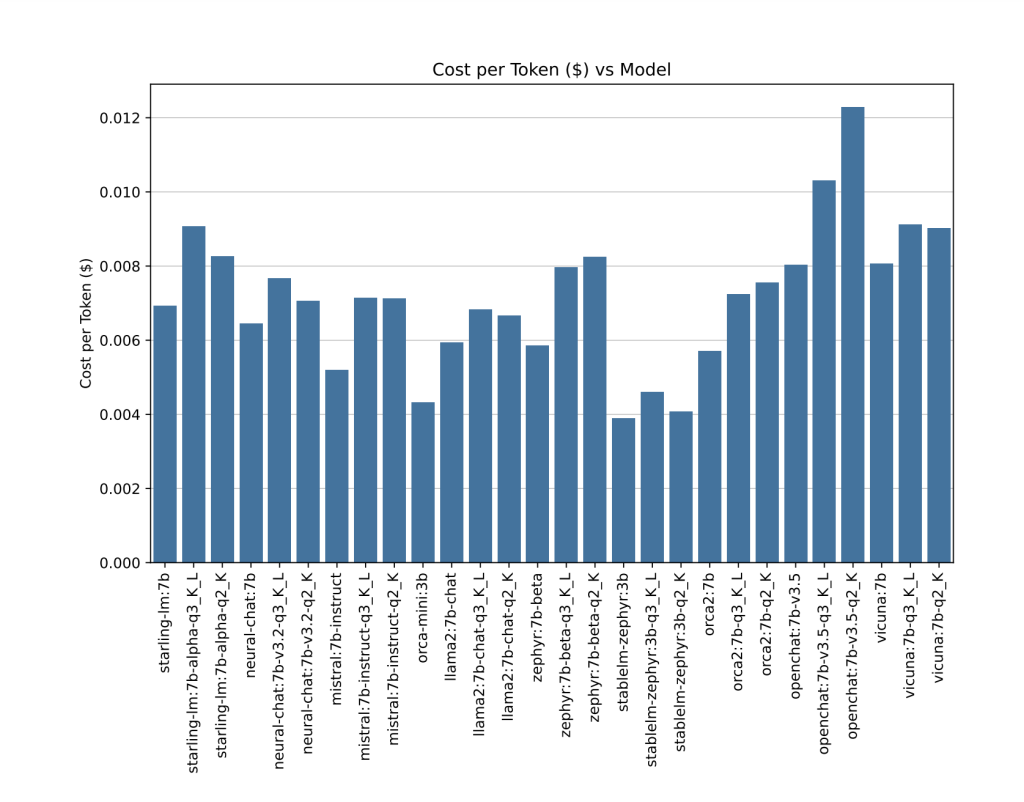
The chart above shows the estimated cost per 1K token generated for each SLM. GPT-4 incurs a cost of $0.03 per input token and $0.06 per completion token, a total of $0.09 whereas the self-hosted SLM models only incur costs associated with AWS.
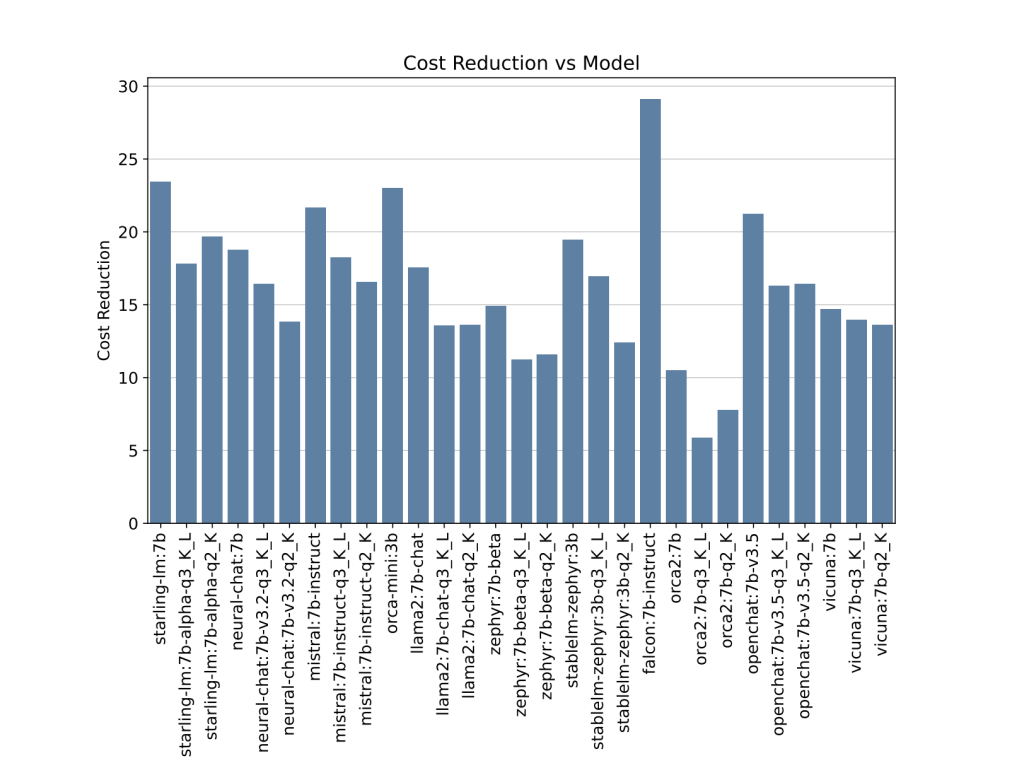
The chart above shows the cost reduction of each SLM, when hosted on g4dn.xlarge AWS node at 80% utilization against OpenAI’s GPT-4 API. Overall, the experiments shows a cost reduction of 5X to 29X, depending on the model used.
Conclusion: SLMs Are the Future of AI in Production
The research highlights that while LLMs like GPT-4 excel in a wide range of applications, smaller and more efficient SLMs are poised to become a popular choice for businesses looking for a more affordable, reliable, and scalable AI solution. With the ability to self-host these models, companies gain full control over their AI infrastructure, leading to predictable performance, reduced latency, and substantial cost savings. Furthermore, the advancements in response quality, particularly with state-of-the-art models like Vicuna and Starling-lm, make SLMs a viable alternative for many production applications, from personalized content generation to customer support.
As the landscape of AI-powered applications evolves, SLMs represent a compelling option for businesses seeking to balance cutting-edge capabilities with operational efficiency. With the right models and infrastructure, companies can harness the power of AI without the financial and technical burdens associated with proprietary LLM services.








.png)


