

Despite the transformative potential of generative AI, its adoption in enterprises is lagging significantly. One major reason for this slow uptake is that many businesses are not seeing the expected ROI from their initiatives; in fact, recent research indicates that at least 30% of GenAI projects will be abandoned after proof of concept by the end of 2025.
The computational and memory requirements of Large Language Models (LLMs) are substantial, often necessitating deployment on expensive cloud infrastructure, which drives up operational costs. To mitigate these costs, there is a growing focus on developing smaller language models (SLMs) that can be deployed on more affordable, edge-based devices. While these models are more cost-efficient, they typically struggle to match the response quality of their larger counterparts.
Existing hybrid inference approaches try to address this issue by directing entire queries to either an SLM or an LLM, based on the predicted difficulty of the query. While these binary routing strategies effectively reduce costs, they may result in suboptimal performance, particularly for more complex queries.
In this context, my team at Bud Ecosystem has developed an innovative approach to address this problem by using a hybrid inference method based on reward-based token modelling. In this approach, we enhance the routing process by evaluating each token individually, enabling a more refined collaboration between the SLM and the cloud LLM. This ensures that cloud resources are only utilised when necessary, preserving both efficiency and response quality. In this article, I shall dive deep into the new hybrid inference approach and evaluate the key results from our experiments. Detailed information on the experiments and evaluations can be found in our research paper:Reward-Based Token Modelling with Selective Cloud Assistance.
Using SLMs running on Intel CPUs, we can ensure cost-effective inference, while hybrid inference with cloud LLMs can mitigate any potential accuracy drop. This strategy allows businesses to balance cost and performance effectively, maximising the potential ROI from their generative AI initiatives that use language models. Let’s see how it works;
Reward-Based Token Modelling with Selective Cloud Assistance
Domain-specific SLMs can offer greater accuracy for industry-specific generative AI use cases. For example, an SLM fine-tuned on financial datasets would likely be more accurate and cost-effective than a generic LLM. However, SLMs may struggle to generalise across diverse topics or tasks, resulting in reduced accuracy for queries requiring broad knowledge.
Our approach uses the SLM as the primary model, evaluating each token it generates for accuracy. If the accuracy falls below a certain threshold, the next token is routed to a cloud LLM, which can compensate for the drop in quality.
This reward-based token modelling employs techniques commonly found in Proximal Policy Optimization for model alignment. In this method, each token produced by the SLM is assessed against a reward function that measures its alignment with the probability distribution of the cloud LLM. Tokens scoring above a set threshold are accepted, while those below it are discarded, prompting the cloud LLM to generate the next token. This strategy ensures that the SLM receives assistance (selective assistance) only when necessary, optimising the balance between high-quality outputs and reduced reliance on cloud resources.
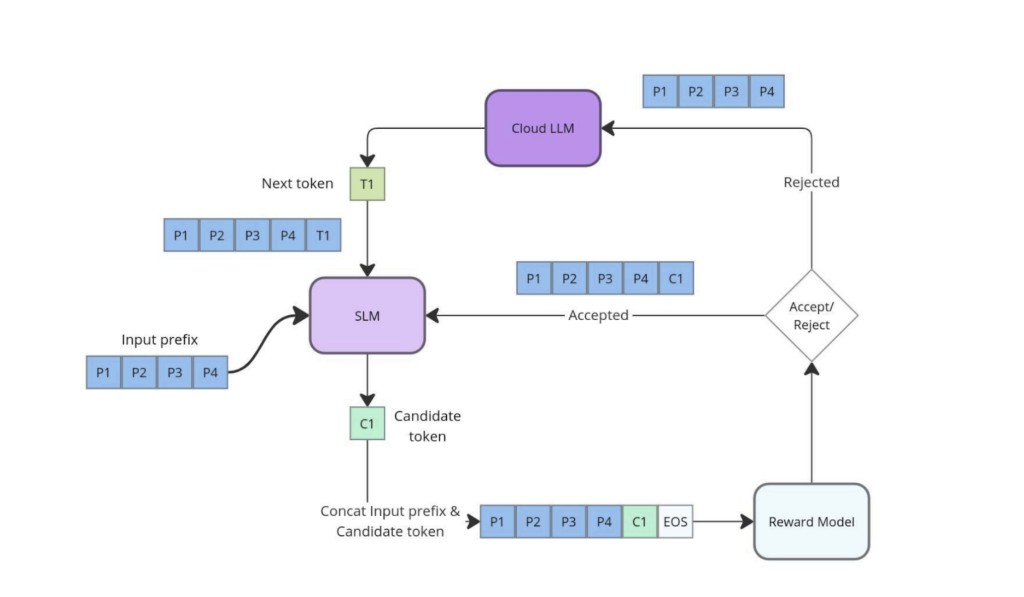
The above diagram illustrates the selective assistance process, wherein the SLM generates candidate tokens that are subsequently scored by the reward model. If a token’s score exceeds the established threshold, it is accepted and incorporated into the sequence. Conversely, if a token is rejected, the cloud LLM generates the next token. This iterative process continues until the sequence is complete, thereby optimising response quality through the selective involvement of the cloud LLM. This method effectively balances the advantages of SLMs with the enhanced capabilities of LLMs, ensuring that the output meets the desired quality standards while minimising reliance on cloud resources.
This approach also allows for fine-grained control over the generation process, enabling dynamic adjustment of the threshold based on context or performance needs. For instance, in scenarios requiring higher precision, the threshold can be raised, increasing the likelihood that the cloud LLM will be invoked. Conversely, in less critical contexts, the threshold can be lowered, allowing the SLM to handle more of the generation, thereby reducing inference latency and cost.
By employing token-level selective assistance, our architecture ensures that each token is evaluated on its own merit, facilitating a more precise and efficient allocation of computational resources between the SLM and the cloud LLM. This method provides a robust framework for deploying hybrid models in real-world applications, where balancing quality and efficiency is paramount.
Experiment Results
To evaluate the effectiveness of our proposed solution, we conducted experiments using the Qwen2 family of models, chosen for their variety of parameter variants. Specifically, we used the Qwen2-0.5B-Instruct model as the reward model due to its efficiency as the smallest model in the series. For data synthesis, we employed the Qwen2-1.5B-Instruct model as the SLM, while the Qwen2-7B-Instruct model served as the LLM. The SLM and reward models were hosted on Intel Xeon processors, while the LLM was hosted on an Nvidia 80GB A100. The table below shows the key results.
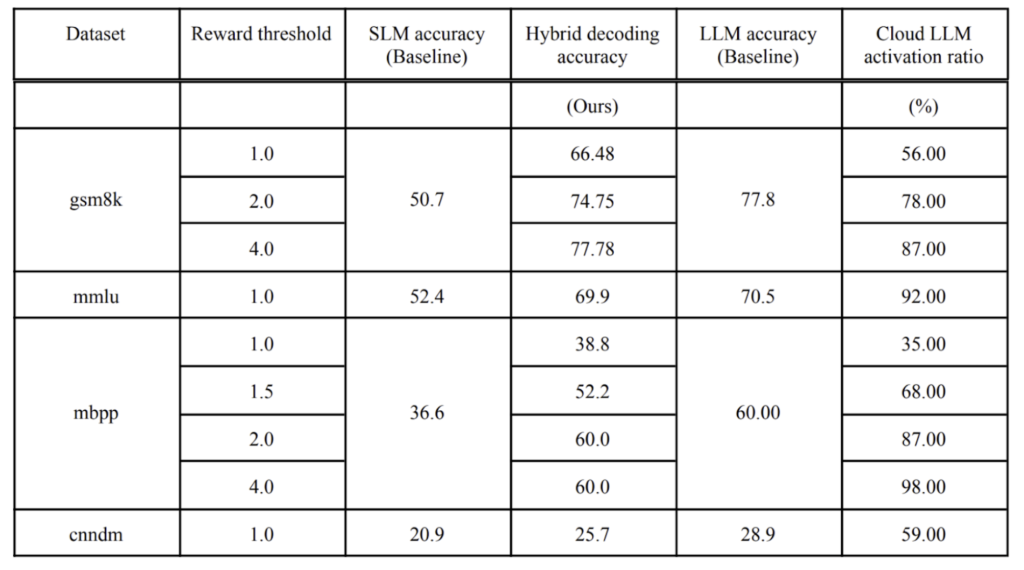
The results presented in the above table demonstrate the effectiveness of our approach in balancing quality and efficiency in token generation by selectively involving the cloud LLM only when necessary.
The reward threshold plays a crucial role in determining the activation of the cloud LLM during the hybrid decoding process. A higher threshold sets stricter criteria for accepting tokens generated by the SLM, resulting in increased reliance on the cloud LLM for token predictions. Conversely, a lower threshold allows for the acceptance of more tokens from the SLM, thereby reducing the activation ratio of the cloud LLM and improving efficiency.
As observed in the evaluation results across various datasets, the cloud LLM activation ratio directly correlates with the reward threshold. For instance, in the GSM8K dataset, setting the reward threshold to 1.0 results in a cloud LLM activation ratio of 56%. As the threshold increases to 2.0 and 4.0, the activation ratio rises to 78% and 87%, respectively. This pattern holds across most datasets, demonstrating that a higher reward threshold drives the architecture toward greater reliance on the cloud LLM for generating tokens, particularly in more complex or nuanced tasks.
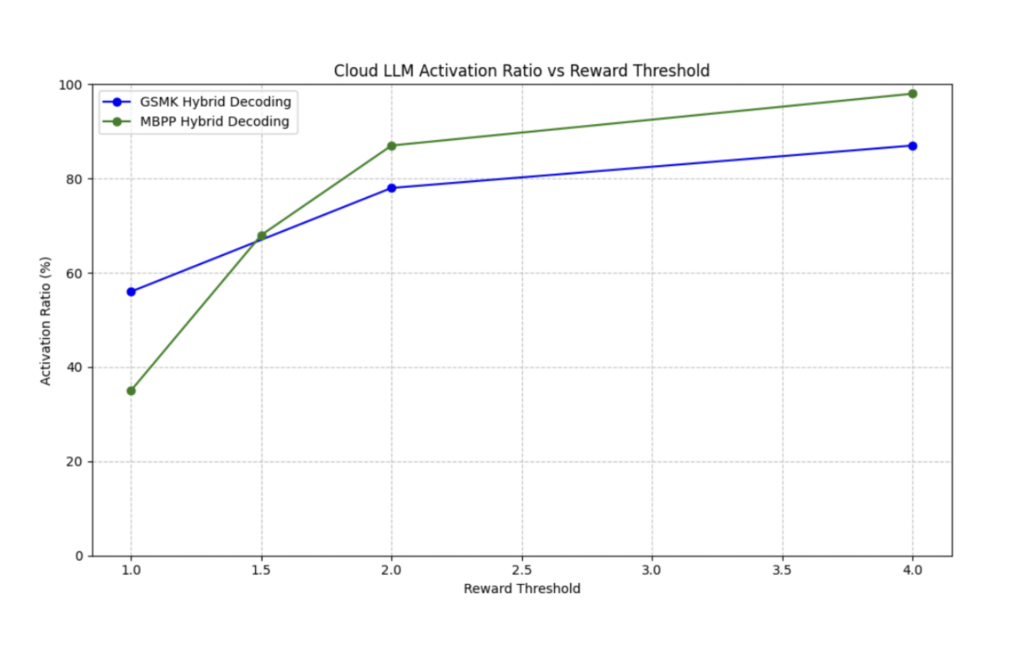
The graph above plots the Reward Threshold against the Activation Ratio of the LLM. For example, a reward threshold of 1 results in only 38.8% LLM activation during the MBPP evaluation. This means a 61.2% reduction in the usage of the cloud LLM and its associated inference costs. When using SLMs that are fine-tuned on domain-specific datasets, the reward threshold value can be lowered, resulting in lesser LLM activation.
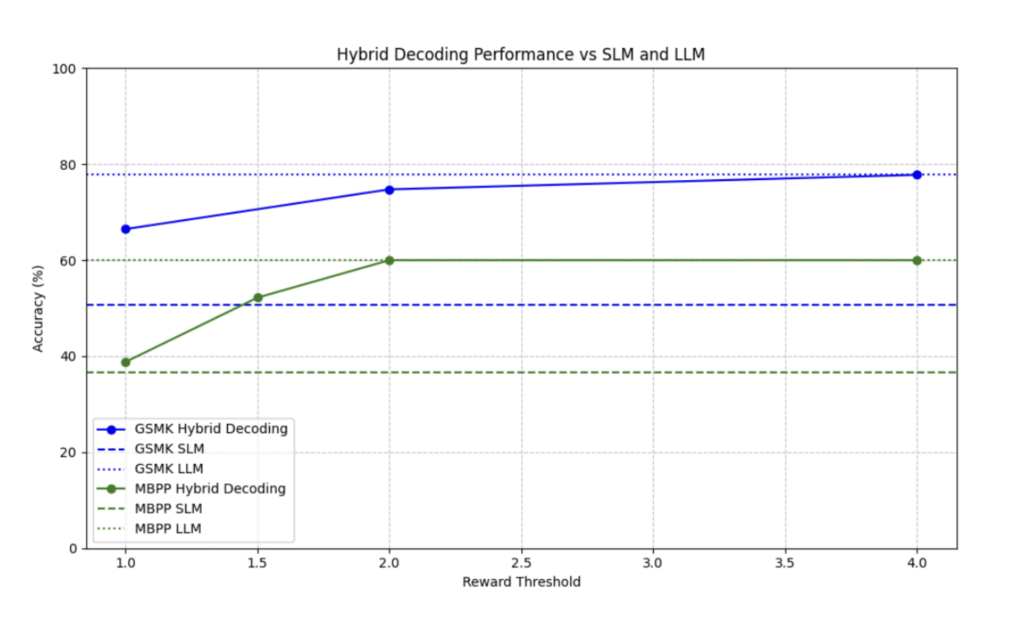
The graph plots the Reward Threshold against accuracy. It shows that the hybrid approach consistently delivers accuracy higher than that of the SLM, with the added flexibility to match the accuracy of the cloud LLM for critical tasks.
Future Considerations
Our proposed architecture demonstrates substantial improvements in efficiency and flexibility for hybrid decoding, yet some challenges require attention. Efficient routing between models relies heavily on an accurate reward model, and misalignments can impact both quality and resource efficiency. The need to recalibrate reward models for new SLM-LLM pairs and the potential inference time overhead when routing frequently to the cloud LLM can also be a challenge.
To mitigate these limitations, future advancements could focus on cache mechanisms to reduce redundant calls, which would optimise latency. Additionally, implementing a key-value cache for the LLM could enhance inference speed by reusing attention data across sequences, while a dynamic reward threshold would allow for more adaptive routing based on token complexity. Strengthening SLM-LLM alignment and exploring multi-model collaboration can further enhance the system, reducing reliance on the cloud LLM and improving both performance and accuracy.
These strategies present pathways to enhance scalability, reduce latency, and improve the adaptability of our framework, making it more robust for real-world, latency-sensitive applications. By continuing to refine these mechanisms, we aim to provide an optimised solution that balances efficiency with the computational power needed for high-quality language model deployments.








.png)


