

Summary: The current industry practice of deploying GenAI-based solutions relies solely on high-end GPU infrastructure. However, several analyses have uncovered that this approach leads to resource wastage, as high-end GPUs are used for inference tasks that could be handled by a CPU or a commodity GPU at a much lower cost. Bud Runtime’s heterogeneous inference feature addresses this problem by intelligently splitting the inference workload between CPUs, commodity GPUs, and high-end GPUs, optimizing cost efficiency. This article explores LLM serving using heterogeneous hardware clusters in detail and reviews prominent research in this area.
The cost of serving large language models (LLMs) is one of the key challenges hindering the widespread adoption of generative AI in enterprises. As a result, companies are increasingly focused on making their generative AI initiatives more cost-effective without compromising performance. In recent years, various technical innovations have enhanced inference efficiency, helping to reduce LLM serving costs. While most advancements have concentrated on optimizing inference engines, a crucial factor often overlooked is the optimization of hardware utilization—specifically, using the right hardware for each LLM task.
The current industry practice of deploying GenAI-based solutions relies solely on high-end GPU infrastructure—either on-premises GPU clusters or cloud-based LLM services. These infrastructure options come with significant costs. For instance, serving a model like Llama2-70B at BF16 precision requires two NVIDIA A100-80GB GPUs, which can cost over $5,200 per month in on-demand rental fees on major cloud platforms.
However, several analyses have uncovered that this approach leads to resource wastage, as high-end GPUs are used for inference tasks that could be handled by a CPU or a commodity GPU at a much lower cost. For example,
- For small request sizes, the A10G GPU provides up to 2.6X greater T/$ than the A100 GPU.
- For larger request sizes, the A100 GPU outperforms the A10G by 1.5X in cost efficiency.
In real-world applications, a substantial portion of the requests sent to LLMs are relatively simple and could easily be handled by less powerful hardware, such as CPUs or commodity GPUs. Relying solely on high-end GPUs for all requests leads to a clear inefficiency, wasting valuable resources. Moreover, most deployments already include CPUs, which are often underutilized, further worsening this inefficiency.
This results in significant resource waste and unnecessary costs. By leveraging available compute power from CPUs or commodity hardware, organizations could achieve substantial cost savings without compromising performance for simpler tasks.
At Bud Ecosystem, our research has been dedicated not only to refining inference optimization techniques but also on smarter hardware utilization strategies. An example of this is the hybrid inference feature, which combines cloud-based LLMs with local, specialized models. This method can cut inference costs by up to 60% while maintaining accuracy. Such hybrid strategies offer a powerful means to optimize both cost and performance.
Recently, there is growing interest in using heterogeneous hardware clusters to further enhance cost efficiency. Early research into this area is showing promising results, particularly when combining different types of hardware tailored to specific tasks within the LLM inference pipeline. Bud Runtime’s heterogeneous inference feature intelligently splits the inference workload between CPUs, commodity GPUs, and high-end GPUs, optimizing cost efficiency. In this article, we’ll explore how using heterogeneous hardware clusters to serve LLMs can improve cost-efficiency, making GenAI more accessible and sustainable for businesses looking to take advantage of its potential.
Solely relying on high-end GPU infrastructure for your GenAI deployment leads to overspending. Bud Runtime’s heterogeneous inference splits the workload between high-end GPUs, commodity GPUs, and CPUs to maximize cost-aware hardware utilization, resulting in cost savings of up to 77%.
What is Heterogeneous Inferencing?
Heterogeneous inferencing refers to the use of different types of hardware, such as CPUs, GPUs, TPUs, and specialized accelerators, to perform tasks in a model inference process. Rather than relying on a single type of hardware for the entire inference workload, heterogeneous inferencing leverages the strengths of different hardware components for different tasks, optimizing performance and cost-efficiency.
For example, a CPU might handle less computationally intensive tasks, while a GPU or TPU can be used for more complex processing. This approach allows for better resource allocation, faster processing, and reduced costs, as different hardware can be chosen based on the specific requirements of the inference tasks. In the context of LLMs, heterogeneous inferencing can be particularly useful in reducing operational costs while maintaining or improving model performance.
Heterogeneous inference can be implemented in several ways, depending on the specific needs of the workload. One approach is to use different hardware architectures, such as combining CPUs and GPUs. In this case, the CPU can handle lighter, less resource-intensive tasks, while the GPU takes on the heavier computational workload. Another method involves using different types of GPUs, where a lower-end GPU is used for smaller or simpler tasks, while a higher-end GPU is reserved for more complex and demanding operations. This strategy allows for more efficient resource utilization, ensuring that each task is handled by the most appropriate hardware, optimizing both performance and cost-effectiveness.
LLM Serving with Heterogenous GPUs
This method uses a mix of different GPU types, each suited to the specific task. Rather than using the same GPU for all tasks, resources can be allocated strategically based on factors like request size, rate, and Service-Level Objectives (SLOs), helping to reduce inference costs.
One way to optimize this allocation is through adaptive scaling frameworks like Mélange, which dynamically adjust resource allocation to ensure optimal performance while minimizing costs. By tapping into a blend of GPU types and strategically scaling resources, LLM services can dramatically cut down expenses, making them more cost-effective and accessible to a wider range of users.
Measuring GPU Cost Efficiency
When evaluating the cost efficiency of GPUs in LLM serving, a key metric to consider is tokens per dollar (T/$). This metric measures how many tokens (input and output) are processed for every dollar spent on the GPU’s on-demand rental cost over a given period. Interestingly, there is no single GPU that universally delivers the highest T/$ across all request sizes. The ideal GPU for a given task depends on three key factors:
- Request Size: The size of an LLM request is determined by its input and output token lengths. Lower-end GPUs tend to provide better T/$ for smaller request sizes, while high-end GPUs shine when handling larger requests.
- Request Rate: The volume of incoming requests also plays a critical role in GPU selection. Low request rates are better served by cheaper GPUs, while higher request rates benefit from a mix of GPU types to optimize overall resource allocation.
- Service-Level Objective (SLO): For services with stringent SLOs requiring low-latency responses, high-end GPUs are a necessity. On the other hand, services with more flexible SLOs can save costs by utilizing lower-end GPUs.
Research has shown that no single GPU type is universally optimal for all request sizes. Instead, different GPUs excel in specific request size ranges. For example:
- For small request sizes, the A10G GPU provides up to 2.6× greater T/$ than the A100 GPU.
- For larger request sizes, the A100 GPU outperforms the A10G by 1.5× in cost efficiency.
The bottom line? A mix of GPU types can improve cost efficiency by as much as 72%, compared to using a single GPU type across all request sizes.
Expanding the analysis to include additional GPU types and larger model variants, such as Llama2-70B, further reinforces this trend. As request sizes increase, the most cost-efficient GPU shifts from lower-end options to higher-end GPUs. This highlights the need for a dynamic GPU selection process that adapts to the characteristics of each request.
Adaptive Scaling for Cost Savings
LLM services often experience periods of low activity, during which high-end GPUs may be underutilized. In such instances, it’s crucial to right-size the system by allocating lower-end GPUs when demand drops. This adaptive approach brings several benefits:
- Higher GPU utilization: Ensures GPUs are being used more effectively, even during periods of low demand.
- Lower serving costs: Reduces the need for expensive GPU resources when they are not required.
- More efficient resource scaling: Adjusts the system to ensure that resources are allocated in the most cost-effective manner possible.
Mélange adaptive scaling framework uses a combination of request size, request rate, and SLOs to determine the minimal-cost GPU allocations. Evaluations of Mélange have demonstrated impressive results, showing cost savings of up to 77% compared to strategies that rely on a single GPU type. Even more remarkable, Mélange maintains over 99.5% adherence to SLOs, proving that substantial cost reductions don’t have to come at the expense of service quality.
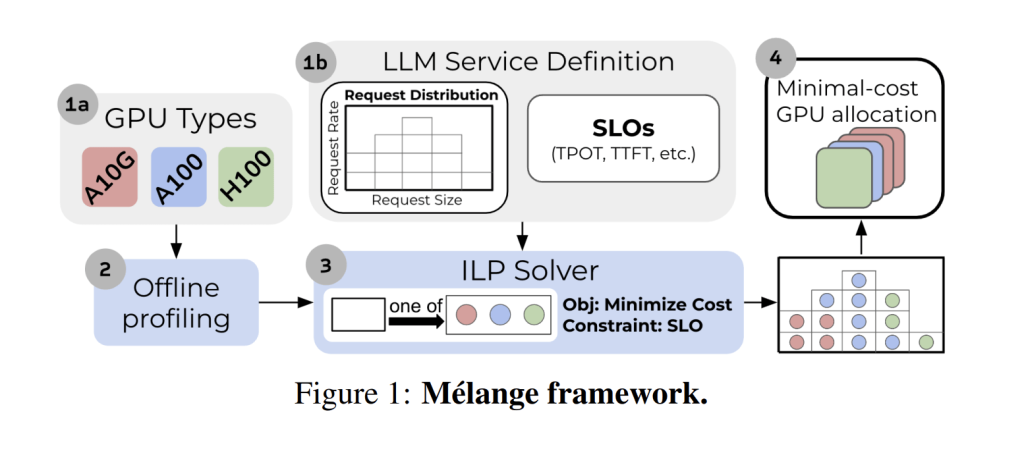
Figure above depicts Mélange GPU allocation framework. It works by first profiling the performance of each GPU type through an offline step. Using this data and the LLM service definition, Mélange determines the most cost-effective GPU allocation for the workload. This problem is framed as a cost-aware bin packing problem, where GPUs are bins and workload slices are items. Mélange formulates the problem as an integer linear program (ILP) and solves it with an off-the-shelf solver. The result is an optimal GPU allocation that meets the service’s service-level objective (SLO) at minimal cost.
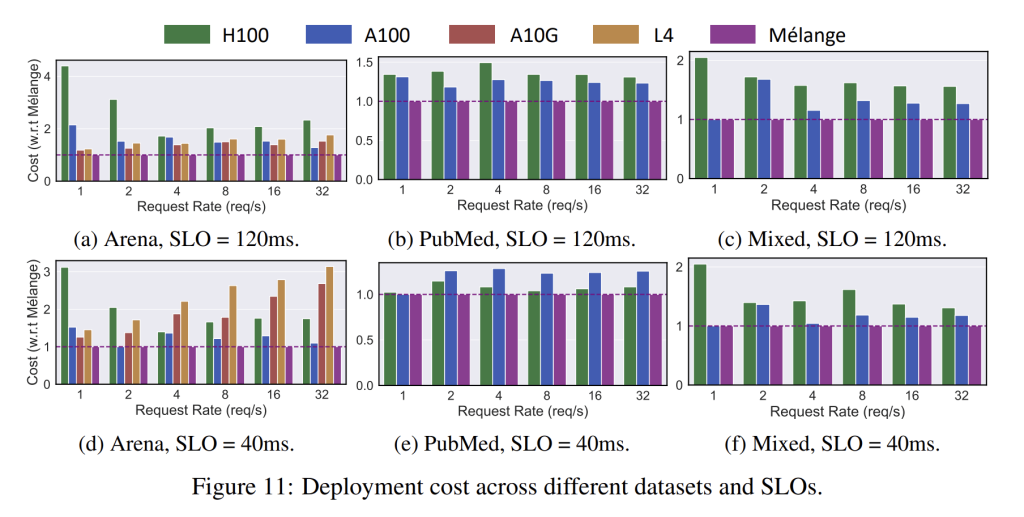
The results plotted above shows that request size, SLO, and request rate all jointly determine cost efficiency. As any of these LLM service characteristics vary, Mélange flexibly adjusts its GPU allocation and mixes GPU types to exploit their heterogeneity. This consistently delivers the most cost efficient allocation across each evaluated dataset with both strict (40ms) and loose (120ms) SLOs, achieving up to a 77% cost reduction.
Heterogeneous parallel computing using CPUs and GPUs.
Heterogeneous parallel computing using different hardware architectures, say, CPUs and GPUs together is more challenging and complex because we have to deal with the diversities and capability differences. Implementing this type of heterogeneous inference comes with a unique set of challenges.
- High memory requirements: LLMs often need tens or even hundreds of gigabytes of memory for inference, which makes it difficult to deploy them on low-resource devices.
- I/O bottlenecks: Data transfer between the CPU and GPU is much slower than the GPU’s computational capabilities, and even slower than the CPU itself, with a speed difference of more than ten times. This inefficiency makes the traditional method of loading all parameters from the CPU to the GPU problematic.
- Optimal parallel strategy: It is difficult to determine the best approach to effectively utilize both CPU and GPU resources for inference.
- Efficient computation distribution: Deciding how to best allocate computation between the CPU and GPU is key to achieving optimal performance.
- Reducing latency: Improving the usage of I/O and CPU computation is crucial to minimize inference latency.
- Load balancing and communication overlap: The large difference in processing speeds between the CPU and GPU can cause issues with load balancing and communication overlap. CPU computations and I/O operations can be tens or even hundreds of times slower than GPU computations.
- Challenges in pipeline parallelism: Challenge of effectively balancing the computation and communication between the CPU and GPU. This includes managing CPU idleness during GPU computations, which micro-batching can mitigate but becomes difficult with sparse input data; allocating operators with varying computation times, which can lead to idle time if not perfectly matched with communication durations; and the GPU’s limited memory capacity, which restricts the ability to stack more layers into a single pipeline stage, making it harder to achieve optimal time balance.
HeteGen approach introduces a principled framework for heterogeneous parallel computing. It combines techniques like hybrid heterogeneous parallelism with an asynchronous parameter manager to improve both inference speed and resource utilization, especially on resource-constrained devices. HeteGen takes a holistic view of the CPU-GPU interaction, strategically managing the distribution of tasks and the flow of data to ensure that both processors are used optimally.
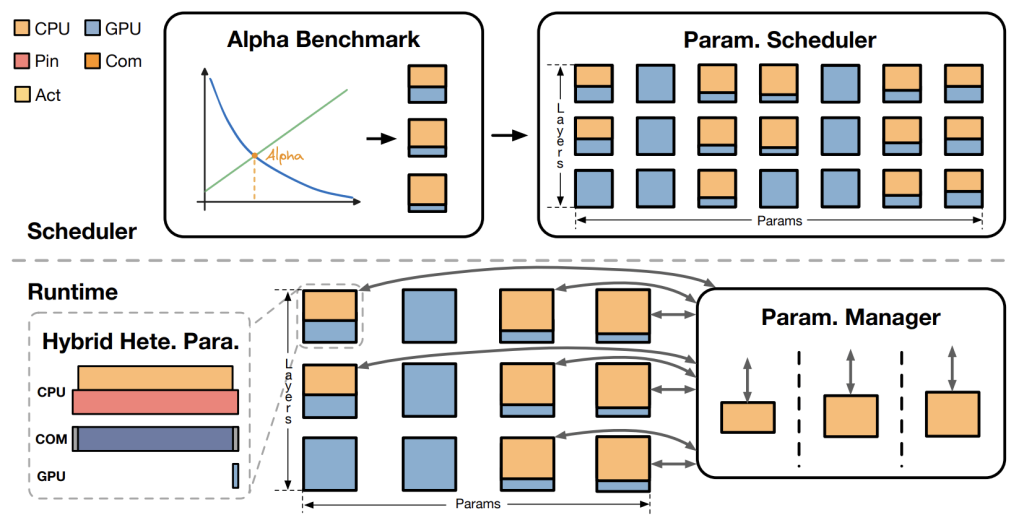
Figure above depicts an Overview of HeteGen. HeteGen has two main stages: scheduling and runtime. In the scheduling stage, it uses the alpha benchmark to distribute computation and decides on parameter policies based on our scheduler. In the runtime stage, it optimizes I/O and CPU utilization within heterogeneous modules using hybrid parallelism and manages asynchronous weights to minimize system impact.
This approach not only accelerates inference but also minimizes unnecessary communication costs, paving the way for more efficient LLM serving on a wide range of hardware configurations. It delivers several key results that highlight its effectiveness in optimizing inference speed and resource utilization:
- Substantial Improvement in Inference Speed: HeteGen significantly enhances inference speed, outperforming state-of-the-art methods by up to 317%. This improvement addresses the challenge of achieving low-latency LLM inference, particularly on devices with limited resources.
- Outperformance of Baseline Methods: HeteGen consistently surpasses baseline methods such as DeepSpeed Inference, HuggingFace Accelerate, and FlexGen, achieving faster speeds with lower memory utilization. For instance, DeepSpeed Inference faced out-of-memory issues when handling larger models like OPT-13B and OPT-30B, whereas HeteGen handled these models effectively without such limitations.
- Wider Range of Dynamic Offload Adjustments: HeteGen offers a much broader range of dynamic offload adjustments for balancing GPU and CPU utilization. For example, with the OPT-30B model, HeteGen adapts GPU memory usage between 6.5% and 88.7%, while FlexGen’s range is limited to just 6.5% to 26.5%. This flexibility showcases HeteGen’s advanced scheduling strategy, allowing for more effective resource management.
- Effective Resource Utilization: A runtime breakdown analysis of the OPT-13B model reveals that HeteGen effectively utilizes both CPU and I/O resources. The time spent on pin memory operations is shorter than that spent on I/O operations, indicating successful overlap between these tasks. This highlights HeteGen’s ability to tackle I/O bottlenecks and optimize resource usage through hybrid heterogeneous parallelism.
- Significant Contributions from Key Components: An ablation study indicates that the alpha benchmark and asynchronous parallelism are crucial to HeteGen’s performance. The heterogeneous module scheduler also plays a vital role in its efficiency, with the absence of this component leading to a significant performance drop.
- Generality and Effectiveness: HeteGen proves its broad applicability by improving inference latency, even when hardware cannot fit all model parameters on the GPU. The offloading strategy is applicable to other large language models with similar Transformer architectures, including LLaMA, GPT-3, and BLOOM.
HeteGen addresses key challenges such as parallel strategy, computation distribution, I/O bottlenecks, and asynchronous operation management. Through its novel heterogeneous parallel computing framework, HeteGen achieves low-latency LLM inference on resource-constrained devices, outperforming existing state-of-the-art offloading techniques and demonstrating strong general applicability.
In conclusion,
The rise of heterogeneous inference represents a transformative shift in optimizing the cost-effectiveness and efficiency of serving LLMs. By intelligently distributing the workload across a combination of CPUs, commodity GPUs, and high-end GPUs, organizations can significantly reduce their operational costs while maintaining high performance. Traditional reliance on high-end GPUs alone leads to resource wastage and inefficiencies, especially for tasks that don’t require such powerful hardware. Innovations like Bud Runtime’s heterogeneous inference and HeteGen’s hybrid parallelism offer practical solutions to these challenges, helping businesses optimize both hardware utilization and inference speed.
With advancements in adaptive scaling and smarter hardware management, companies can now dynamically allocate resources based on the specific demands of each task, cutting costs by up to 77%. Furthermore, techniques like the Mélange adaptive scaling framework and HeteGen’s asynchronous parameter management demonstrate that substantial cost savings can be achieved without sacrificing the quality of service or model performance. As the industry continues to evolve, these innovations pave the way for more accessible, sustainable, and efficient deployment of generative AI solutions across enterprises, making the promise of AI more attainable for a wider range of users.








.png)


