

In the research paper “Kangaroo: Lossless Self-Speculative Decoding via Double Early Exiting,” the authors introduce a new framework called Kangaroo designed to make large language models (LLMs) run faster. This framework enables the training of a smaller, lightweight model in a cost-effective way.
This new framework is introduced to speedup the text generation process of LLMs, especially when using a method called Speculative Decoding (SD). Here’s a simplified breakdown of the challenges the authors wanted to solve with their research;
- Memory Bandwidth Bottleneck: Even though LLMs do a lot of mathematical calculations, the real bottleneck or slowdown comes from the time spent moving data in and out (read/write operations) of the memory where the model’s weights are kept.
- Improving Decoding Speed: To make text generation faster, earlier research proposed a method called Speculative Decoding (SD). This involves a “draft” model that predicts several possible next words in parallel, instead of just one at a time. The goal is to quickly generate multiple words and then verify which ones are good. However, this approach has two main issues:
- Draft Model Training: Creating a draft model that can predict well often requires significant resources and time, which isn’t always practical.
- Draft Model Inference Speed: If the draft model itself is slow, it doesn’t help much in speeding up the text generation.
- Self-Drafting Models: Some methods, like LLMA and REST, try to address these issues by generating draft tokens using different strategies without needing a separate draft model. Medusa, for example, uses additional neural network components to create draft tokens, but it still has limitations in the effectiveness of these tokens and their generation speed.
Kangaroo Framework
The authors tackled the challenges of speeding up text generation in large language models using their new framework, Kangaroo. Here’s how they addressed the issues:
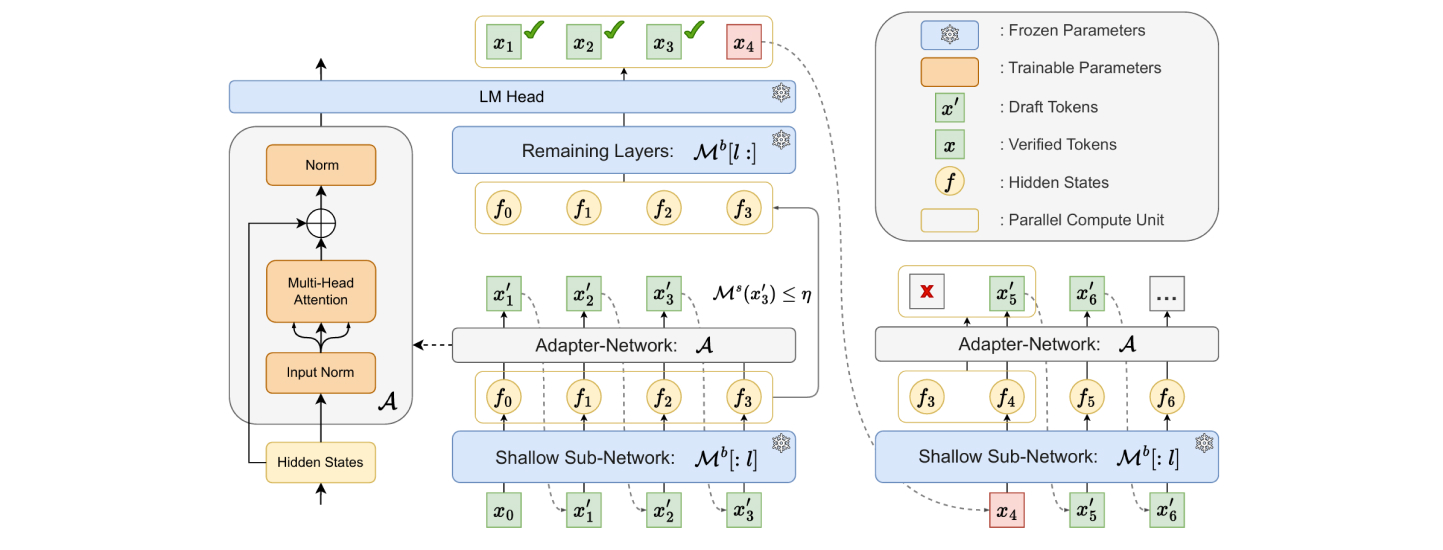
- Autoregressive Self-Draft Model: They designed a lightweight and efficient model called an “autoregressive self-draft model.” This model is built on a fixed, shallow part of the large LLM and uses a small, additional adapter module.
The adapter network, which includes only one multi-head attention layer and two normalisation layers, has only 11.3% of the parameters compared to Medusa-1’s heads. Despite its simplicity, this design proves to be both efficient and powerful.
- Early Exiting Mechanism: To further reduce latency, they implemented an early exiting mechanism during the draft token generation phase. This mechanism allows the model to exit early from processing when it’s generating simpler tokens, thus avoiding unnecessary computation for more complex tokens.
- Self-Speculative Decoding Framework: They introduced the Kangaroo framework, which uses a double early-exit mechanism. First, the smaller self-draft model exits early from the shallow layers of the large LLM and connects to the adapter network to generate draft tokens. Second, it applies early exiting during the drafting phase to minimize computational overhead on difficult tokens.
- Low-Cost Training and Deployment: Kangaroo offers a cost-effective way to train a lightweight model. Since the self-draft model and the large LLM share some of the KV cache and computation, the primary additional requirement for deployment is a small adapter network.
- Performance Validation: The authors validated Kangaroo’s effectiveness through experiments on the Spec-Bench benchmark. Kangaroo achieved up to a 1.7× speedup compared to Medusa-1 while using 88.7% fewer additional parameters (67 million vs. 591 million).
In summary, the authors improved text generation speed by creating a lightweight model with a simple architecture and an efficient early exiting mechanism, thereby reducing computational costs and latency while maintaining performance








.png)


