

We are excited to announce the open-source release of Maxwell Task Complexity Scorer v0.2, a breakthrough in efficient instruction complexity scoring. Maxwell represents a significant advancement in task complexity analysis, offering State-of-the-Art performance in a remarkably efficient package.
Maxwell leverages a ModernBERT-Large backbone to deliver sophisticated complexity scoring while maintaining exceptional efficiency. With a dense Token-to-Parameter ratio of 3.5:1, Maxwell achieves scoring capabilities comparable to models 34 times its size, including established solutions like HKUST’s DEITA Complexity Scorer.
View model card in HuggingFace: budecosystem/Maxwell-TCS-v0.2
Technical Highlights
- Training Data: Trained on 66.5K diverse instruction-score pairs
- Architecture: Built on ModernBERT-Large backbone
- Efficiency: Optimized Token-to-Parameter ratio of 3.5:1
- Performance: Matches or exceeds GPT-based scorers while maintaining superior processing speed
Applications
Maxwell excels in quantitative measurement of instruction and task complexity, making it particularly valuable for:
- Large-scale NLP applications
- Task complexity analysis
- Efficient annotation workflows
- Research applications requiring rapid complexity assessment
The BERT-based architecture gives Maxwell a significant edge in processing speed and efficiency, especially when handling large datasets. This architectural choice allows Maxwell to maintain high performance while significantly reducing computational requirements compared to GPT-based alternatives.
How does it work?
Maxwell generates a normalized complexity score between 0 and 1 for any given instruction, providing a standardized measure of task complexity. This score can be predicted as a unidimensional score that captures a query’s complexity, length, use of jargon & phrases and the depth of knowledge required to answer such questions.
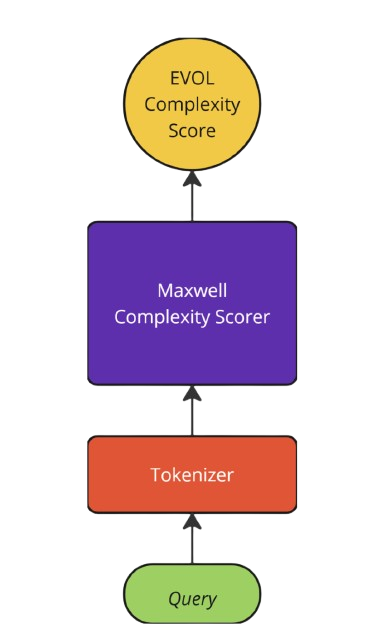
Furthermore, the normalized score predictions can be transformed across different scales which allows for customizability across different use-case scenarios.
The Importance of Complexity Assessment
As GenAI adoption transitions from experimental pilots to mainstream use, businesses are increasingly focused on optimizing their applications for production-level deployment. In this context, balancing performance and efficiency has become a critical priority, as the total cost of ownership (TCO) for these applications is largely determined by how effectively resources are managed. This challenge has emerged as a focal point of current research, particularly in the area of task routing.
To maximize performance, advanced architectures have been proposed that employ strategies like selecting the best response from a set of top candidates (e.g., LLM-BLENDER) or sequentially querying a hierarchy of LLMs until a superior response is identified (e.g., Frugal-GPT). However, these approaches face scalability challenges, particularly in terms of cost efficiency.
Preference-Oriented Routing Approaches (PORA), such as RouteLLM, address this issue by aligning queries with language models based on human preference data. While effective to some extent, these methods fall short in ensuring an optimal match between queries and models, as they do not adequately consider both the specific attributes and requirements of the query and the inherent capabilities of the models.
We believe that the problem of routing is best addressed by adopting a holistic approach that simultaneously evaluates the unique demands of each query and the specialized strengths of available models. This dual-focus strategy ensures more efficient and accurate task allocation, ultimately driving better performance and cost optimization.
In its most simplest form, this dual focused approach could be visualized as Binary Routing Setup:
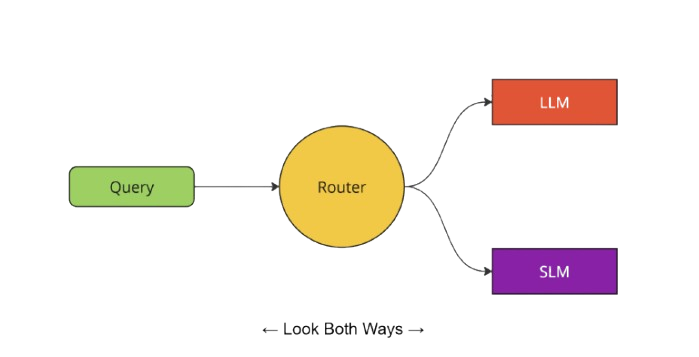
In our framework, the router is tasked with not only selecting the best candidate from a given pair—comprising a strong model and a weaker model—but also making its decision based on both the general and specific attributes of the query. Our proposed approach ensures that the router evaluates both dimensions comprehensively, effectively “looking both ways” to make informed and optimal routing decisions.
Naturally, since LLMs excel at managing complex tasks, it’s logical to assign them high-complexity queries, while simpler tasks can be handled by the more efficient SLM. In this sense, the router essentially becomes a complexity predictor. This is what initially motivated us to create Maxwell. By leveraging task complexity scoring, Maxwell facilitates intelligent task routing, ensuring that each task is assigned to the model most capable of handling it. This approach not only enhances output quality but also reduces the overall cost of operating the application.
Understanding and quantifying task complexity is crucial in human-AI decision-making processes and Maxwell offers a powerful solution for businesses to ensure that their AI applications run both effectively and cost-efficiently, making it an essential tool for scaling GenAI systems in real-world environments.
How to Model Complexity?
Maxwell’s training data is based on the DEITA Evol Complexity scheme, a novel approach for measuring complexity, that is a part of the DEITA framework (Data-Efficient Instruction Tuning for Alignment), which focuses on optimizing data selection and instruction tuning for large language models (LLMs).
Under the DEITA framework, complexity scores for instructions are generated using a systematic process involving instruction evolution and scoring by a language model. The process begins with a seed dataset of instruction-response pairs. Using the Evol-Instruct method, five progressively more complex instructions are generated for each seed instruction. However, it must be noted that unlike the broader Evol-Instruct method, here we do not use in-breadth evolving (e.g., mutation-based variations).

This involves adding constraints, increasing reasoning steps, or introducing more specific details to the instructions.
Now, once we have the prompts ready, an LLM judge is employed to evaluate and rank the complexity of the sextuple (original instruction + 5 evolved instructions). The LLM assigns scores based on the relative complexity and difficulty of each instruction.

Scores are typically assigned on a scale from 1 to 6, where 1 represents the least complex instructions and 6 represents highly complex instructions. This ranking + scoring process ensures that each instruction’s complexity is quantified in a way that reflects its difficulty and sophistication relative to the other instructions. Once a large number of such (instruction, score) pairs has been collected, a complexity scorer can be trained on such a dataset to predict complexity scores for any given instruction.
Use Cases for Maxwell
Maxwell is versatile and can be employed in various downstream tasks. Some of its primary applications include:
- Prompt Difficulty Prediction: By evaluating how complex an input instruction is, Maxwell-TCS helps to predict the difficulty of tasks in prompt engineering, allowing for better-tailored user interactions.
- Dataset Annotation: Maxwell-TCS can be used for automated scoring and annotation of datasets, helping to categorize or label tasks based on their complexity level, facilitating more efficient data preprocessing.
- Dataset Augmentation: Researchers can leverage the model to generate diverse instructions across a range of difficulty levels, augmenting their datasets with complexity labels that help in model training.
- Task Optimization: Developers working on automated task generation can benefit from the tool’s insights, using it to balance task difficulty across datasets or experiments.
Conclusion
Maxwell-TCS-v0.2 marks an exciting advancement in the field of task complexity scoring, offering users a sophisticated tool for assessing and annotating task difficulty with ease. Built on the ModernBERT-Large architecture and trained on a large, diverse dataset, it offers both speed and accuracy, making it a valuable resource for a wide range of NLP tasks. As the field continues to evolve, Maxwell-TCS will undoubtedly play a critical role in refining and optimizing the complexity assessment of tasks, helping both researchers and developers take their work to the next level.








.png)


