

Deepseek’s latest innovation, R1, marks a significant milestone in the GenAI market. The company has achieved performance comparable to OpenAI’s o1, yet claims to have done so at a much lower training cost—a major breakthrough for the industry. However, with 671 billion parameters, R1 remains too large for cost-effective enterprise deployment. While impressive, such massive models still present significant challenges in inference and operational efficiency for enterprise GenAI applications.
The real game-changer, however, isn’t just the model itself but the methodologies Deepseek used to train it, primarily Multi-Head Latent Attention (MLA). Could we use these techniques to train or fine-tune smaller, more cost-efficient models (SLMs)—which are far more practical for real-world enterprise applications? A recent study, TransMLA, introduces a post-training method that transforms pre-trained models like LLaMA, Qwen, and Mixtral into MLA-based models. In this article, we’ll dive into TransMLA and evaluate its effectiveness.
Why Are Large Models Expensive to Train and Fine-Tune?
Large Language Models (LLMs) work by predicting the next word (or part of a word) in a sentence based on the context of what came before. This might sound simple, but it requires massive amounts of computation because the model doesn’t just look at the last word—it considers everything that has been said so far.
To make this process more efficient, LLMs use a technique called key-value (KV) caching. Think of it like taking notes during a conversation—once the model has processed part of a sentence, it remembers (or “caches”) key pieces of information so it doesn’t have to reanalyze the same words repeatedly. This speeds up response times and reduces unnecessary calculations, making the model more efficient and cost-effective.
However, as models become larger, this caching introduces memory and communication bottlenecks:
- Massive GPU Memory Requirements
For example, LLaMA-65B, even with 8-bit KV quantization, requires 86GB of GPU memory to store just 512K tokens. This exceeds the capacity of a single H100-80GB GPU, making large-scale training and inference incredibly demanding. - High Inter-GPU Communication Overhead
Distributing these models across multiple GPUs leads to latency and synchronization issues, further inflating training costs.
These challenges highlight why simply scaling up LLMs isn’t a viable long-term solution for enterprise AI. Instead, focusing on efficient training techniques and smaller, optimized models—like those inspired by Deepseek’s methodology—could provide the real path forward.
How Innovators Are Tackling the Challenge
To address the memory and computational bottlenecks of large-scale model training, researchers have explored various modifications to the attention mechanism:
- Multi-Query Attention (MQA)
Reduces KV cache requirements by using a single attention head for both Key and Value layers. - Group-Query Attention (GQA)
Further optimizes memory by grouping Query heads, allowing each group to share a single Key and Value head.
While these methods help reduce the memory footprint, they often come at the cost of model performance. Additionally, techniques like post-training pruning and KV compression aim to shrink KV sizes but frequently degrade accuracy, necessitating fine-tuning to restore lost performance.
In contrast, Multi-Head Latent Attention (MLA)—first introduced in Deepseek V2, refined in Deepseek V3, and now integral to Deepseek R1—strikes an effective balance between efficiency and accuracy.
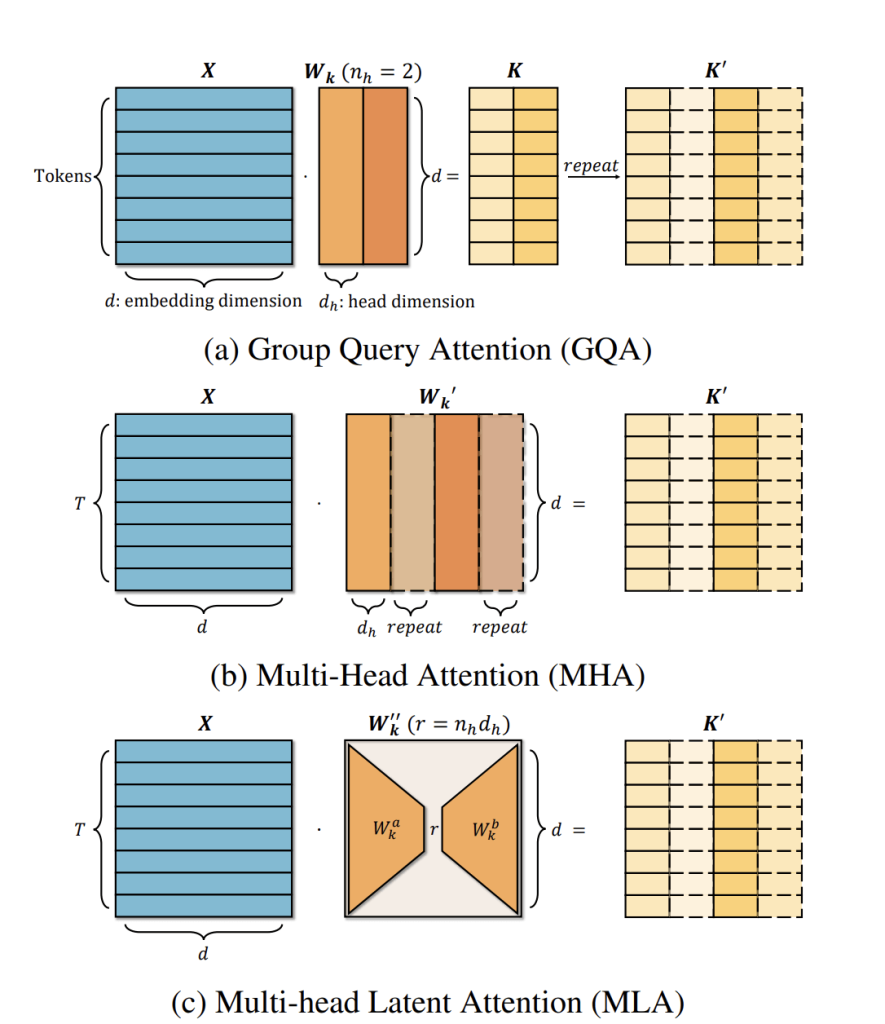
Can MLA Be Applied to Smaller Models?
Deepseek’s use of MLA has proven to be a game-changer, enabling R1 to achieve performance comparable to OpenAI’s O1 at a fraction of the cost. Now, imagine applying these same principles to SLMs—this could result in highly efficient, cost-effective models that bring state-of-the-art performance within reach for enterprises.
This is where TransMLA comes in—a post-training method designed to convert GQA-based pre-trained models (such as LLaMA, Qwen, and Mixtral) into MLA-based models. By shifting the mainstream LLM attention design from GQA to MLA, TransMLA offers a cost-effective migration strategy that unlocks higher accuracy and efficiency while reducing resource consumption and carbon emissions.
At its core, TransMLA reinterprets the GQA “repeat KV” scheme as a low-rank factorization, closely aligning with MLA’s design principles. This insight not only paves the way for more accurate and efficient small models but also demonstrates a practical pathway for enterprises to adopt cutting-edge AI with significantly lower costs.
Evaluating Effectiveness of TransMLA
To assess the impact of TransMLA, the team converted a GQA-based model into an MLA-based model using the Qwen2.5 framework and compared their training performance on downstream tasks.
Model Conversion and Architecture Adjustments
- Qwen2.5-7B has 28 query heads and 4 key/value (KV) heads per layer, with each head having a 128-dimensional representation and a KV cache dimension of 1024.
- Qwen2.5-14B features 40 query heads and 8 KV heads per layer, with the same 128-dimensional heads but a KV cache dimension of 2048.
Upon converting the Qwen2.5-7B model to MLA, several key modifications were made:
- The output dimensions of weight matrices (Wᵃₖ and Wᵃᵥ) were adjusted to 512, while KV cache size remained at 1024.
- Unlike the original GQA model, TransMLA projects the dimensions of Wᵇₖ and Wᵇᵥ from 512 to 3584 (28 × 128), allowing each query head to interact with 28 distinct queries, enhancing the model’s expressive power.
Despite this transformation, the KV cache size remained unchanged, ensuring no additional memory overhead. The increase in parameters was also minimal:
- For the Query-Key (QK) pair, the additional 512 × 3584 matrix was introduced, compared to the original 3584 × 3584 + 512 × 3584 matrix.
- Similarly, for the Value-Output (V-O) pair, the increase in parameters accounted for just 1/8 of the original matrix size.
As a result, the total parameter count increased only slightly, from 7.6 billion to 7.7 billion, making the change negligible in terms of computational cost.
Comparing Fine-Tuning Performance
To evaluate TransMLA’s effectiveness, both the original GQA-based Qwen model and the TransMLA model were trained on the SmolTalk instruction fine-tuning dataset.
- Task-Specific Performance:
- Figure below shows that TransMLA outperformed the original GQA-based model across both 7B and 14B settings.
- The most significant improvements were observed in math and code-related tasks, highlighting better expressiveness and reasoning ability.
- Training Loss: The TransMLA model exhibited a significantly lower loss, indicating stronger data-fitting capabilities.
This performance boost is attributed to two key factors:
- Enlarged Key-Value dimensions – Allowing greater capacity for complex representations.
- Orthogonal decomposition – Enabling more effective feature extraction.
In conclusion,
TransMLA demonstrates that by reengineering attention mechanisms, we can convert large, resource-intensive models into smaller, efficient versions without sacrificing performance. This breakthrough not only reduces memory and computational demands but also enhances key capabilities like reasoning and expressiveness. As a result, enterprises can potentially deploy cost-effective, high-performing GenAI solutions that are both sustainable and practical for real-world applications.








.png)


