



Overview
Earlier research from OpenAI, particularly the Kaplan scaling laws, indicated that increasing the size of model parameters generally leads to improved accuracy and reasoning capabilities of LLMs. As model parameters grow larger, the requirements for computational parallelization and high-bandwidth memory for production-ready inference also increase substantially. This trend poses a significant challenge to traditional CPU-based computing paradigms.
However, by mid-2023, new scaling laws, such as Google’s Chinchilla scaling law, began to reshape the industry. These laws suggest that smaller models trained with an optimal number of tokens can outperform larger models. This was demonstrated by the Chinchilla model from Google and Meta’s LLaMa-2 70B model.
In conjunction with advancements in model architecture—like Mixture of Experts—and innovative training dataset preparation methods, smaller, compute- and memory-efficient models have shown to be more accurate and effective than their larger counterparts. This trend was further validated by models like Phi, Vicuna, Mistral Gemma, Mamba, MiniCPM, and the Bud Jr series.
This evolving paradigm has led to the development of performant small language models ranging from 500 million to 10 billion parameters, as well as midsize LLMs from 10 billion to 40 billion parameters. When combined with efficient model compression techniques and quantization methodologies, these models require significantly less computational parallelization and memory bandwidth.
The Problem
The aforementioned paradigm shift has been recognized by Intel who see it as an opportunity to reduce the total cost of ownership (TCO) and capital expenditures (CapEx) associated with deploying foundational models at scale by leveraging Intel’s infrastructure.
However, the existing software ecosystem was not well-suited for CPU-based generative AI (GenAI) inference. While inference runtimes and serving stacks like OpenVINO, OneAPI, and IPEX excelled with classical and smaller neural networks, they were not designed to handle the demands of generative AI foundational models, such as large language models (LLMs), multimodal language models (MLLMs), diffusion models, and I-JEPA models, which can have billions of parameters and rely on complex attention mechanisms and key-value caches. These models require significant computational parallelization, high-bandwidth memory, and substantial memory overhead.
Furthermore, the methodologies in use at that time necessitated model-specific optimizations, such as quantization and pruning, which often compromised model performance and accuracy.
The Solution
The Bud Runtime, enabled Intel and its customers by providing a production-ready LLM inference runtime, serving engine, and comprehensive end-to-end software stack. This integration led to a remarkable enhancement in LLM performance on CPUs, increasing throughput from 9 tokens per second to an impressive 520 tokens per second. Key improvements included custom kernels optimized for CPUs, memory tiling and other memory optimizations, improved core utilization, key-value (KV) decomposition, attention optimization, and function fusing. These advancements collectively facilitated more efficient and scalable inference for LLMs, maximizing their operational capabilities on Intel’s infrastructure.
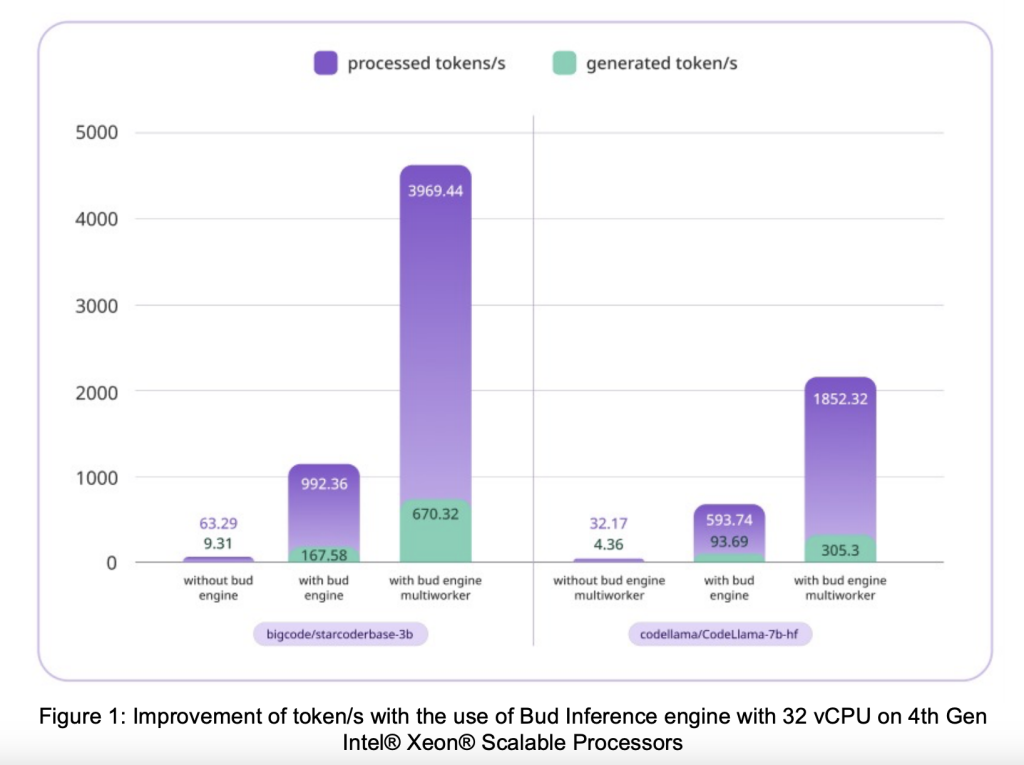
Key Results
The experiments demonstrate significant performance gains in CPU utilization for large language model inference. Key results include:
- Performance Improvement:The inference engine, leveraging AMX on 4th Gen Intel® Xeon® Scalable Processors, achieves an 18x increase in token generation per second for the bigcode/starcoderbase-3b model when using 32 vCPUs and 100 parallel requests.
- Vertical Scaling:Token generation per second improves as the number of vCPUs increases, indicating the engine’s capability to vertically scale with available resources.
- Impact of Request Volume:Performance also enhances with an increase in the number of requests. Higher vCPU counts require a larger number of requests to optimize resource utilization fully.
- Scalability and Practicality:Scalability and Practicality: The findings confirm that parallelized inference on CPUs effectively enhances throughput, making large language models more feasible for real-world applications.
- Future Research Directions:The study suggests further research opportunities and optimizations to boost the efficiency of large language model inference on CPUs.



.png)


