




Overview
Bud Ecosystem, Intel, and Tech Mahindra collaborated on benchmarking Project Indus, an innovative open-source language model designed specifically for Hindi and its dialects. Focusing on applications within the Indian linguistic landscape, Project Indus aims to enhance natural language generation and processing capabilities.
The benchmarking study emphasises key performance metrics such as Time to First Token (TTFT), inter-token delay, input prompt length, output prompt length, and total throughput in tokens per second. By evaluating these parameters under various conditions, including different numbers of concurrent requests, a detailed performance profile of the Indus LLM on Intel® AI hardware was obtained. The results highlight the model’s effectiveness and scalability, offering valuable insights for optimising its practical implementation. You can access the full solution brief for more details here.
The Problem
India is a linguistically diverse country with 1,645 dialects and 27 official languages. Hindi alone has over 600 million speakers and encompasses numerous dialects, some of which are spoken by more than a million people. Existing models from top firms have struggled to effectively respond to inquiries in these various dialects. To address this issue, it is essential to develop a foundational model in Hindi that comprehensively includes all its dialects. Moreover, LLMs carry a significant carbon footprint, making them environmentally unsustainable, whether used for training or inference.
The Solution
Makers Lab, the innovation team at Tech Mahindra, developed Project Indus, a large language model (LLM) specifically for Hindi and its 37 dialects. The project began with an extensive data collection effort, resulting in the world’s largest dataset for these languages, totaling 100 GB. The model, which includes 1.2 billion parameters and 22 billion tokens, was created with a budget of $150,000 and a team of 15 people. It was trained using CDAC GPUs, consisting of 48 powerful A100 GPU computers.
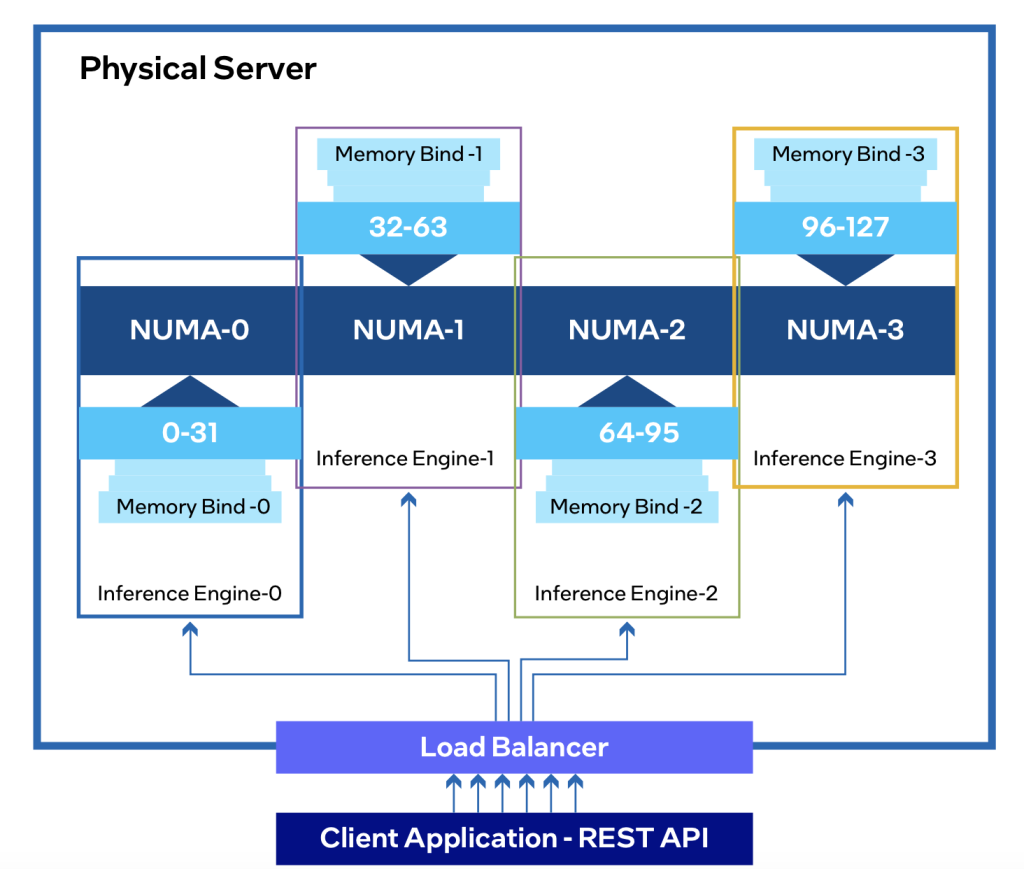
The fine-tuned Indus model is implemented for inference on a platform powered by 5th Gen Intel® Xeon® processors. Intel collaborated with Bud Ecosystem to develop a custom version of the model, integrating Bud Runtime and an inference stack to enhance functionality. The solution is optimized to leverage Intel® Advanced Matrix Extensions (Intel® AMX) and Intel® Advanced Vector Extensions 512 (Intel® AVX-512), improving inference performance.
NUMA (Non-Uniform Memory Access) architecture considerations were incorporated to address memory performance issues, ensuring efficient parallel application processing. The model was validated and benchmarked using the LLMPerf library, which involved load tests to measure inter-token delay and generation throughput for both individual and concurrent queries.
Benefits offered by Bud Runtime
Intel collaborated with Bud Ecosystem to develop a custom version of the model, integrating Bud Runtime and an inference stack to enhance functionality. The benefits offered by Bud includes;
- High Throughput and Concurrency:The engine supports the creation of portable and production-ready LLM applications, providing high throughput and concurrency. This is achieved on Intel® Xeon® processors from the 4th, 5th, and 6th generations, ensuring efficient handling of large-scale applications.
- State-of-the-Art Optimization:Bud Runtime employs advanced optimization methods to enhance performance and security. This includes ensuring the best total cost of ownership (TCO) for return on investment (ROI) and performance-driven applications.
- Enhanced Performance:The engine utilises Intel® Advanced Matrix Extensions (Intel® AMX) and Intel® Advanced Vector Extensions 512 (Intel® AVX-512) to improve inference serving performance, optimising computational efficiency and data processing.
- Scalable Architecture:Bud Runtime supports ‘Across the Box Scale Out’ and ‘In-Box Scale Out’ approaches with Sub NUMA (Non-Uniform Memory Access) clusters, addressing memory performance issues and enabling efficient parallel application processing.
- Unified API and Toolchain:It provides a singular API set and toolchain for seamless integration and deployment, streamlining the development and management of LLM applications.
Key Results
The Indus Language Model has undergone extensive benchmarking on the Intel platform, demonstrating robust performance across several critical areas. These include Time to First Token (TTFT), inter-token latency, input prompt length, output prompt length, and overall throughput (measured in tokens per second) at varying levels of concurrent requests.
- Throughput:The model achieves an average of 33.9984 tokens per second, demonstrating robust throughput capabilities.
- Response Time:The total response time ranges from 0.249 to 4.27 seconds for processing 22 to 167 tokens, with an average end-to-end latency of 3.07 seconds.
- Time to First Token (TTFT):For 2 NUMA nodes and 100 concurrent requests, TTFT was 8.03 secondsFor 90th percentile requests with 200 concurrent requests, TTFT was 17.18 seconds.
- Performance Comparison:The performance of the Indus LLM is comparable to GPU inference, indicating its efficiency.
- Scalability:The model’s performance scales effectively with the number of NUMA nodes and maintains high throughput even with increased concurrent requests
- Responsiveness:The Indus LLM shows impressive responsiveness and versatility, handling various linguistic tasks with low inter-token latency and effective performance across different input and output prompt lengths.
Overall, the Indus LLM proves to be a robust, versatile, and efficient model for natural language processing tasks, demonstrating strong scalability and performance on the Intel platform.



.png)


