

Our vision is to simplify intelligence—starting with understanding and defining what intelligence is, and extending to simplifying complex models and their underlying infrastructure.




Part 1 : Methods, Best Practices and Optimisations Part 2: Guardrail Testing, Validating, Tools and Frameworks (This article) As large language models (LLMs) become more powerful, robust guardrail systems are essential to ensure their outputs remain safe and policy-compliant. Guardrails are control mechanisms (rules, filters, classifiers, etc.) that operate during deployment to monitor and constrain an […]

Part 1 : Methods, Best Practices and Optimisations (This article)Part 2: Guardrail Testing, Validating, Tools and Frameworks As organizations embrace large language models (LLMs) in critical applications, guardrails have become essential to ensure safe and compliant model behavior. Guardrails are external control mechanisms that monitor and filter LLM inputs and outputs in real time, enforcing […]

The global AI landscape shows a significant gap in infrastructure between developed and developing countries. For instance, the United States has about 21 times more data center capacity than India. This research shows that software-based optimization strategies, architectural innovations, and alternative deployment models can greatly reduce reliance on large infrastructure. By analyzing current capacity data, […]

In the fast-moving world of Generative AI, where innovation often outpaces regulation, licensing has emerged as an increasingly critical—yet overlooked—challenge. Every AI model you use, whether open-source or proprietary, comes with its own set of licensing terms, permissions, and limitations. These licenses determine what you can do with a model, who can use it, how […]
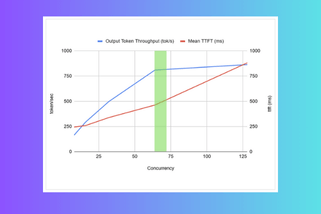
When deploying Generative AI models in production, achieving optimal performance isn’t just about raw speed—it’s about aligning compute with user experience while staying cost-effective. Whether you’re building chatbots, code assistants, RAG applications, or summarizers, you must tune your inference stack based on workload behavior, user expectations, and your cost-performance tradeoffs. But let’s face it—finding the […]

Beyond the high costs associated with adopting Generative AI (GenAI), one of the biggest challenges organizations face is the lack of know-how to build and scale these systems effectively. Many companies lack in-house AI expertise, cultural readiness, and the operational knowledge needed to integrate GenAI into their workflows. Based on a survey of over 125 […]

Generative AI adoption is skyrocketing across industries, but organizations face a critical choice in how to deploy these models. Many use third-party cloud AI services (e.g. OpenAI’s APIs) where they pay per token for a hosted model, while others are investing in Private AI – running AI models on-premises or in hybrid private clouds. There […]

India, being one of the most linguistically diverse nations in the world, faces a major roadblock in harnessing the full potential of Generative AI. With only about 10% of the population fluent in English, the remaining 90% are effectively left behind—unable to engage with GenAI tools that are predominantly built for English-speaking users. Most leading […]

Open-source large language models (LLMs) have become foundational to modern enterprise AI strategies. Their accessibility, performance, and flexibility make them an attractive choice for developers and businesses alike. However, as adoption grows, so does a quiet but serious threat: supply chain attacks via model downloads & execution. When you pull a model from Hugging Face […]
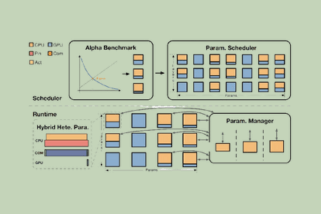
Summary: The current industry practice of deploying GenAI-based solutions relies solely on high-end GPU infrastructure. However, several analyses have uncovered that this approach leads to resource wastage, as high-end GPUs are used for inference tasks that could be handled by a CPU or a commodity GPU at a much lower cost. Bud Runtime’s heterogeneous inference […]
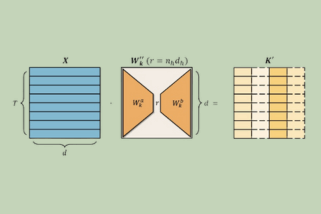
Deepseek’s latest innovation, R1, marks a significant milestone in the GenAI market. The company has achieved performance comparable to OpenAI’s o1, yet claims to have done so at a much lower training cost—a major breakthrough for the industry. However, with 671 billion parameters, R1 remains too large for cost-effective enterprise deployment. While impressive, such massive […]
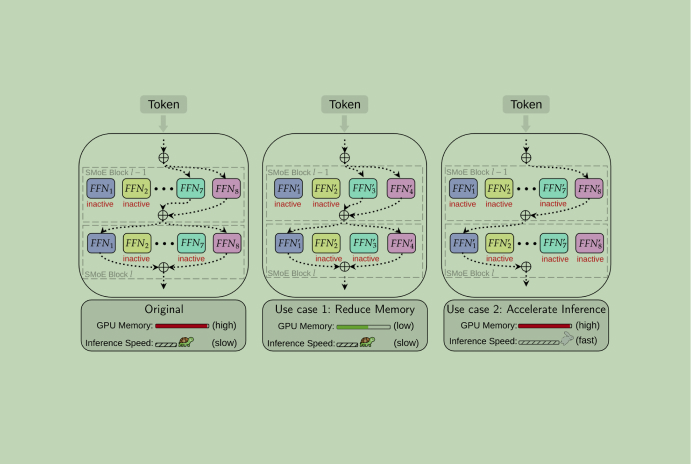
As LLMs continue to grow, boasting billions to trillions of parameters, they offer unprecedented capabilities in natural language understanding and generation. However, their immense size also introduces major challenges related to memory usage, processing power, and energy consumption. To tackle these issues, researchers have turned to strategies like the Sparse Mixture-of-Experts (SMoE) architecture, which has […]
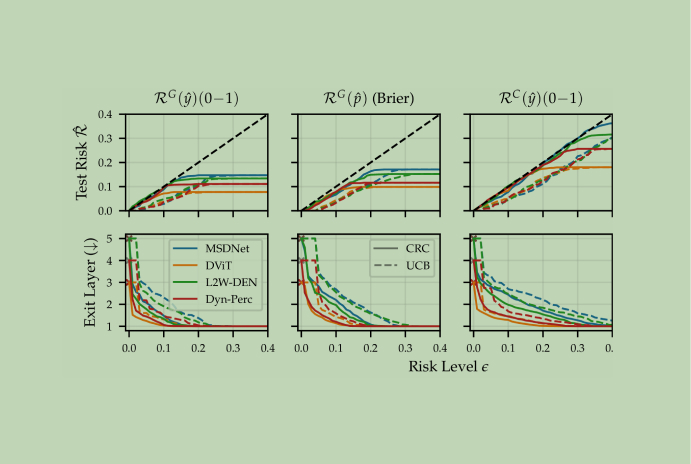
Large Language Models, with their increased parameter sizes, often achieve higher accuracy and better performance across a variety of tasks. However, this increased performance comes with a significant trade-off: inference, or the process of making predictions, becomes slower and more resource-intensive. For many practical applications, the time and computational resources required to get predictions from […]
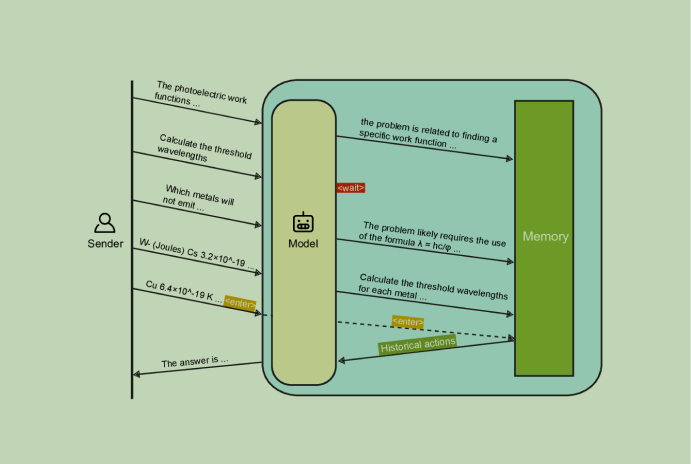
In the rapidly evolving world of artificial intelligence, large language models (LLMs) are making headlines for their remarkable ability to understand and generate human-like text. These advanced models, built on sophisticated transformer architectures, have demonstrated extraordinary skills in tasks such as answering questions, drafting emails, and even composing essays. Their success is largely attributed to […]
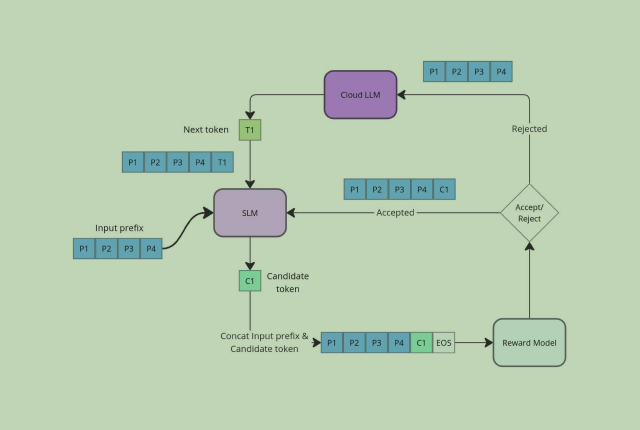
Despite the transformative potential of generative AI, its adoption in enterprises is lagging significantly. One major reason for this slow uptake is that many businesses are not seeing the expected ROI from their initiatives; in fact, recent research indicates that at least 30% of GenAI projects will be abandoned after proof of concept by the end of […]
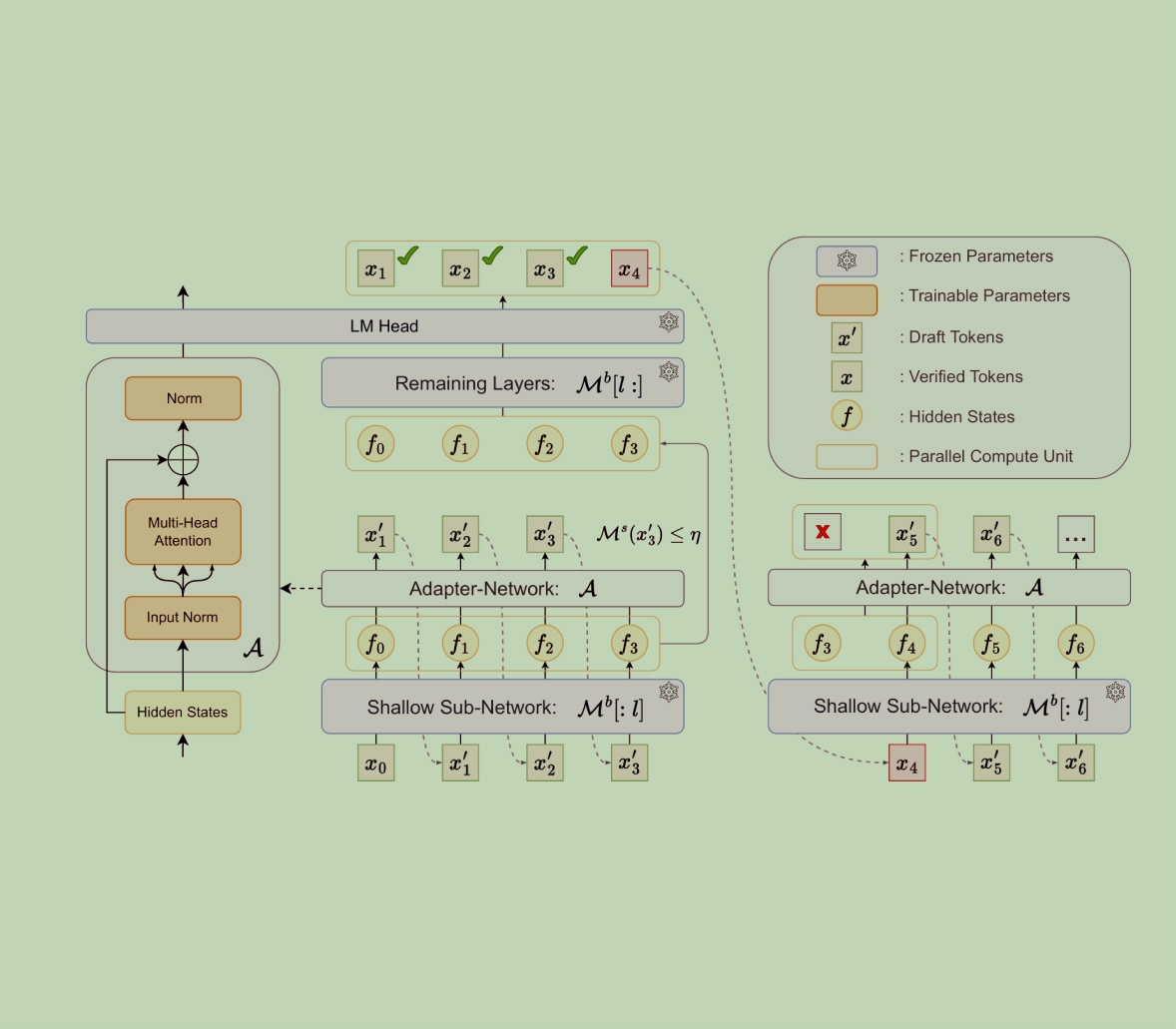
In the research paper “Kangaroo: Lossless Self-Speculative Decoding via Double Early Exiting,” the authors introduce a new framework called Kangaroo designed to make large language models (LLMs) run faster. This framework enables the training of a smaller, lightweight model in a cost-effective way. This new framework is introduced to speedup the text generation process of […]
GenAI Made Practical, Profitable and Scalable!
.png)



© 2024, Bud Ecosystem Inc. All right reserved.