

As organizations experiment with proof-of-concept and pilot projects for enterprise-grade Generative AI applications, the primary focus often remains on developing functionality rather than optimizing for operational efficiency. However, when transitioning from experimental phases to deploying production-ready GenAI applications, business leaders quickly realize that efficiency is paramount. This is because the total cost of ownership (TCO) of GenAI solutions is heavily influenced by how effectively the application utilizes available hardware infrastructure.
Given that GenAI applications are typically compute-intensive, ensuring the optimal use of hardware resources is crucial. Enterprise GenAI applications often involve multiple modalities and tasks, all of which must be processed using limited hardware resources. Unfortunately, many existing large language model (LLM) serving systems are ill-equipped to handle these complexities, leading to inefficiencies.
In light of these challenges, a recent innovation in the field—named Chameleon—proposes a novel LLM serving system that optimizes performance in environments with many adapters. In this article, we will dive deep into the Chameleon approach and explore how it addresses these inefficiencies, ultimately paving the way for more efficient, cost-effective GenAI deployments.
Overlooked inefficiencies in LLM inference
In a typical production-ready GenAI deployment, the application supports multiple modalities and task capabilities that users engage with concurrently. These tasks often span a variety of downstream applications, such as chatbot conversations, coding, or text summarization. To achieve optimal performance, each task requires specialized fine-tuned large language models (LLMs).
The Challenge
LLMs, with their billions of parameters, impose significant hardware and energy demands on data centers. Each model requires substantial memory to store its multi-billion-parameter structure, which presents a scalability challenge.
Adapter-based techniques, such as Low-Rank Adaptation (LoRA), have been explored to address this issue. These methods focus on fine-tuning only a small subset of a base model’s parameters for each task, reducing the resource requirements compared to fine-tuning the entire model. In LLM inference serving environments, this approach enables the decoupling of the base model parameters from the task-specific adapter parameters, allowing multiple fine-tuned models to share the same base. This sharing of the base model reduces memory consumption significantly, enabling the serving of potentially hundreds of LoRA-fine-tuned LLMs at a fraction of the memory cost.
Despite the memory reduction achieved in multi-task settings, this approach introduces two new challenges that have not been encountered before.
Asynchronous adapter fetching increases TTFT latency
When adapter-based techniques are used for LLM inference, the inference clusters must also manage and orchestrate the adapters needed for incoming requests as they are scheduled. In many popular LLM inference systems, the required adapters are fetched on-demand in advance and discarded once the request is complete. However, studies show that this asynchronous adapter fetching increases the time-to-first-token (TTFT) latency, particularly under heavy system load. This results in high TCO for LLM deployments. This is because it leads to higher contention for the CPU-GPU PCIe link bandwidth.
The diagram above shows results from a TTFT analysis experiment and it is observed that as the rank size of adapters increases, the adapter overheads also increase. For example, for rank 128, ∼60% of the total TTFT latency is spent on adapter loading and computation.
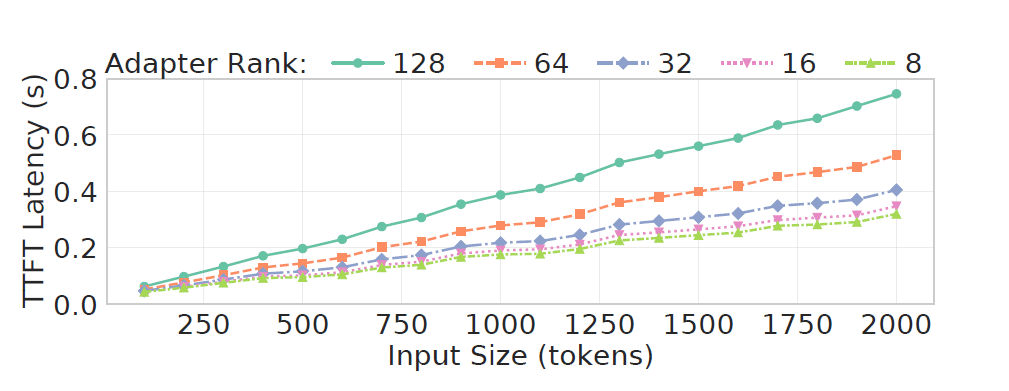
The graph above shows the increasing TTFT latency for different adapter ranks as we increase the input size of a request, i.e. the number of input tokens, while keeping the output size fixed. These results point out that adapters are an additional source of heterogeneity in LLM inference that must be managed dynamically.
Head of line blocking
In addition to the loading costs, adapters also introduce inference overheads, which increase the execution time of individual queries. To improve resource utilization, some existing methods employ techniques such as batching and clustering of heterogeneous requests. However, these approaches can lead to workload heterogeneity, load imbalances, and frequent request migration at the server level, which may undermine their effectiveness. This results in head-of-line blocking, which occurs in a system when the first request in a queue (the “head” of the line) experiences delays, causing all subsequent requests in that queue to also be delayed, even if they could have been processed independently and more quickly.
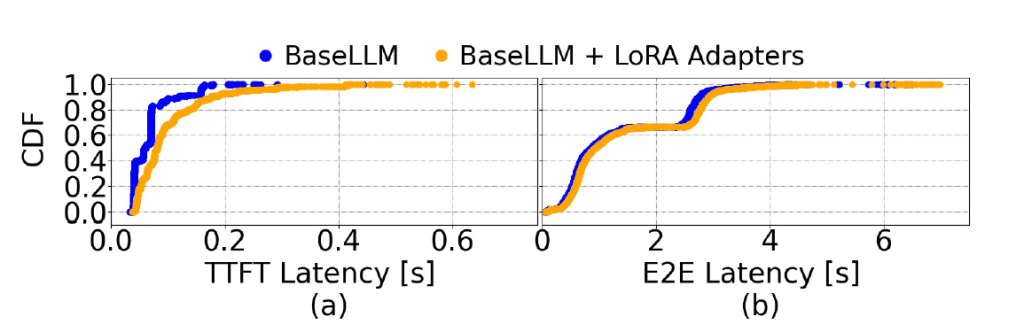
The figure above illustrates that, in a real production environment, LLM inference requests are highly heterogeneous, with execution times following a heavy-tail distribution: most requests have very short execution times, while a few have significantly longer execution times.
Conventional systems typically use a FIFO (First-In, First-Out) approach due to its simplicity. However, FIFO is inefficient for handling heterogeneous requests, as it introduces head-of-line blocking, which increases tail latency. An alternative approach, Shortest-Job-First (SJF), attempts to predict a request’s output length and prioritizes those with shorter predicted outputs. However, this continuous prioritization of short requests leads to the starvation of longer requests, further worsening tail latency.
As a result, conventional scheduling policies like FIFO and SJF are ineffective for managing highly heterogeneous LLM inference requests. There is a need for a scheduling policy that can efficiently handle request heterogeneity while considering all factors that influence execution time.
How Chameleon Solve These Problems
To address the challenges mentioned above, a more sophisticated scheduling strategy is required. A method that considers adapter-level heterogeneity and accelerates the processing of short requests. It must also ensure that longer requests still meet their Service Level Objectives (SLOs). The Chameleon LLM serving system is designed to achieve exactly this.
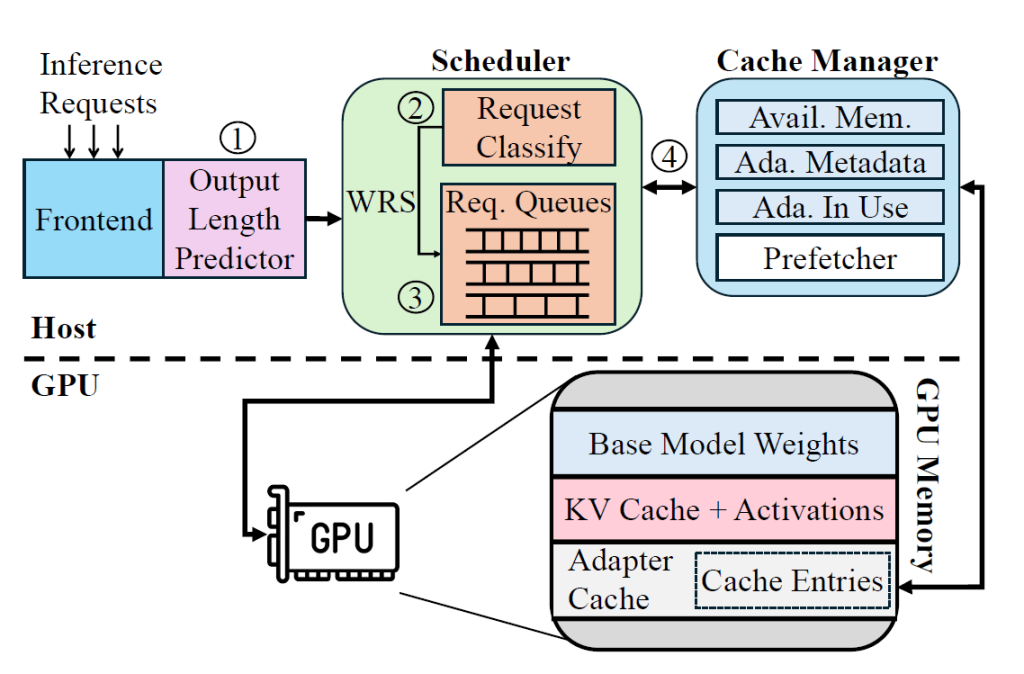
The figure above provides an overview of Chameleon’s architecture. To effectively manage workload heterogeneity, Chameleon classifies incoming requests based on their total size. Each request is first processed by an output length predictor, which estimates the number of output tokens.
How? The Chameleon scheduler combines this estimated output size with the number of input tokens and the adapter rank required for the request to calculate a weighted request size (WRS). Chameleon uses WRS to categorize requests into different classes—such as small, medium, and large—and assigns them to appropriate request queues.
Chameleon employs iteration-level scheduling, meaning that at each decode iteration, requests are added and removed from a batch. Importantly, the scheduler uses requests from all queues while respecting their assigned quotas. Each queue is allocated a certain amount of GPU resources, which requests from that queue can consume during each iteration. This approach creates a fast lane for short requests, preventing head-of-line blocking, while ensuring that requests from all queues are processed, avoiding starvation.
To adapt to load fluctuations and changing request characteristics, Chameleon dynamically adjusts both the number of queues and the per-queue cutoffs based on the WRS distribution of incoming requests. Additionally, the Cache Manager plays a crucial role in every scheduling decision. It manages the Chameleon Adapter Cache and is responsible for:
- Prefetching any necessary adapters required by the requests to be scheduled.
- Evicting idle adapters when GPU memory is insufficient to store incoming requests’ input, output, and key-value (KV) cache entries.
The Cache Manager tracks all cached adapters along with the necessary metadata to enforce a cost-aware eviction policy, ensuring that resources are efficiently utilized. Chameleon delivers high efficiency through two key principles.
Transparent, adaptive and interference-free cache for adapters
There is often sufficient idle GPU memory, even during periods of high load. The available idle GPU can be repurposed to cache adapters likely to be reused and expensive to reload. However, as idle memory fluctuates, Chameleon dynamically adjusts the size of its cache based on the incoming load. This helps prevent interference with the key-value cache and other memory allocations for requests.
To manage this, Chameleon integrates its cache manager with the system scheduler. This allows it to dynamically adjust cache resources in real-time while continuously monitoring incoming request traffic. Additionally, Chameleon employs a cost-aware eviction policy that takes into account both the recency and frequency of adapter use, as well as the reloading cost, to determine which adapters to discard when the cache reaches capacity or needs to shrink.
This scheme assigns a score to each adapter based on three factors: its frequency of use, recency of access, and size. The score is calculated using the formula:
Score = F × Frequency + R × Recency + S × Size
Here, F, R, and S are weighting coefficients that determine the importance of each factor. The adapter with the lowest score is considered the least critical and is evicted first. This approach effectively balances the trade-offs between evicting adapters that are infrequently used, haven’t been accessed recently, or are large in size, ensuring that the most important adapters are retained in the cache.
Non-preemptive adapter-aware multi-level queue scheduler
Chameleon uses a non-preemptive, adapter-aware multi-level queue (MLQ) scheduler to reduce head-of-line blocking and ensure that service level objectives (SLOs) are met for all types of requests. The system assigns priorities to incoming requests using a weighted request size (WRS) metric. WRS factors in the number of input tokens, an estimated output length, and the adapter rank for each request. Chameleon then allocates resources based on the priorities of the queues. This approach creates a faster processing path for smaller requests while preventing starvation of larger ones. To further optimize performance and guarantee SLOs across all request types, Chameleon dynamically adjusts the number of queues and their resource allocations in real-time.
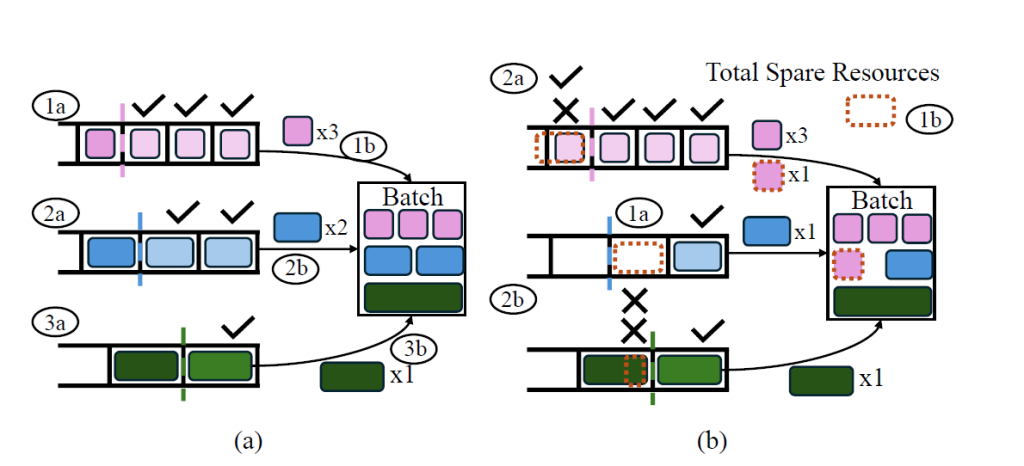
The figure above illustrates the queuing process, which involves three request queues for “short”, “medium”, and “large” requests. In Figure (a), the Initial Request Admission phase is depicted. During this phase, requests are assigned to the appropriate queues based on their characteristics. In Figure (b), the system shows a scenario where spare resources are available for redistribution. This allows the system to allocate additional resources to queues that may require more capacity to process their requests.
However, if a request at the head of a queue cannot be admitted to the batch due to insufficient memory for its adapter, all requests within that queue are blocked. This blockage occurs because the system cannot process the head request without the necessary resources. As a result, no requests from that queue can proceed until resources become available.
Key Results
To evaluate the performance of Chameleon, experiments were conducted on a server equipped with an NVIDIA A40 GPU and an AMD EPYC 9454 CPU. The GPU has 48GB of memory, while the CPU is configured with 48 cores and 377GB of main memory. The majority of the experiments used the Llama-7B model. For scalability testing, additional experiments were performed on a server with an NVIDIA A100 GPU, configured with 24GB, 48GB, and 80GB of GPU memory.
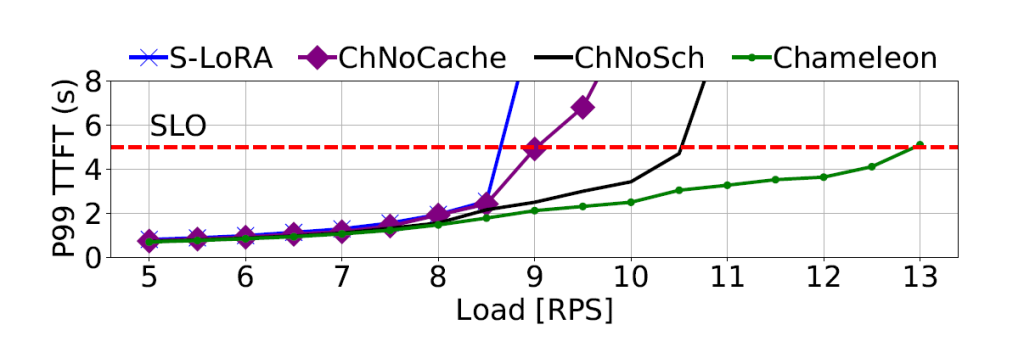
The figure above presents the P99 time-to-first-token (TTFT) tail latency for S-LoRA and Chameleon under varying loads. The results show that Chameleon consistently outperforms the baseline, with its advantages becoming more pronounced as the load increases. Additionally, Chameleon achieves 1.5× higher throughput compared to S-LoRA, demonstrating its superior performance in handling high loads.
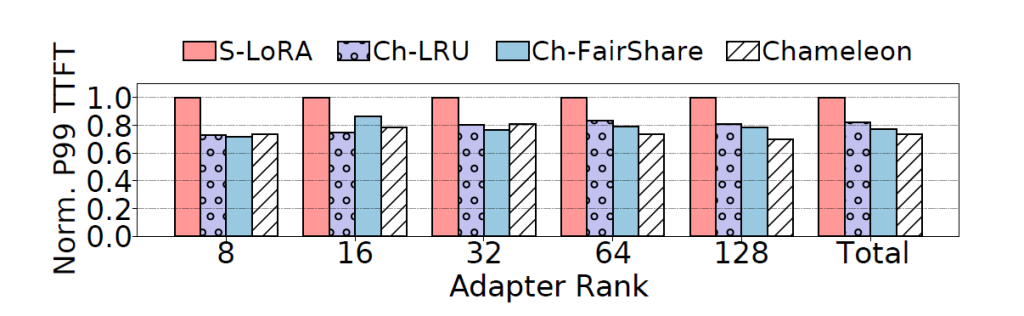
The figure above shows the normalized P99 TTFT latency for requests with different adapter ranks, using various caching policies, at medium system load. It is observed that Chameleon’s proposed caching mechanism is highly effective. All caching schemes reduce the P99 TTFT latency compared to the baseline, with significant improvements across all adapter ranks. Furthermore, the proposed replacement policy further enhances performance, particularly for larger adapters, demonstrating its effectiveness in optimizing cache management.
Results! Under high loads, Chameleon reduces P99 and P50 TTFT latency by 80.7% and 48.1%, respectively. At the same time, it improves throughput by 1.5× compared to state-of-the-art baselines.
Bottomline,
In conclusion, Chameleon offers a powerful solution to the inefficiencies faced in multi-adapter LLM inference environments. By integrating adaptive caching, dynamic scheduling, and cost-aware eviction policies, it effectively manages resource allocation, reduces latency, and prevents head-of-line blocking. With its ability to optimize performance and resource usage, Chameleon significantly improves both the throughput and efficiency of GenAI applications. This innovation paves the way for more scalable, cost-effective, and high-performance deployments, helping businesses achieve their goals while managing the increasing demands of enterprise-grade GenAI systems.








.png)


