


Generative AI unlocks incredible capabilities, but it doesn’t come cheap. Training and deploying large models like LLMs or diffusion models demand massive compute, making the total cost of ownership (TCO) a serious concern for teams building production-grade systems.
To make GenAI cost-effective and scalable, you need to squeeze out every bit of performance from your infrastructure. That means leveraging every optimization strategy available—efficient scheduling, smart memory usage, quantization, and one of the most powerful tools in the toolbox: parallelism.
Parallelism allows workloads to run concurrently across machines, dramatically improving throughput, reducing latency, and enabling models that would otherwise be too large to handle. It’s a foundational technique for building efficient GenAI systems. In this article, we’ll break down the different types of parallelism methods and highlight notable research and innovations on each.
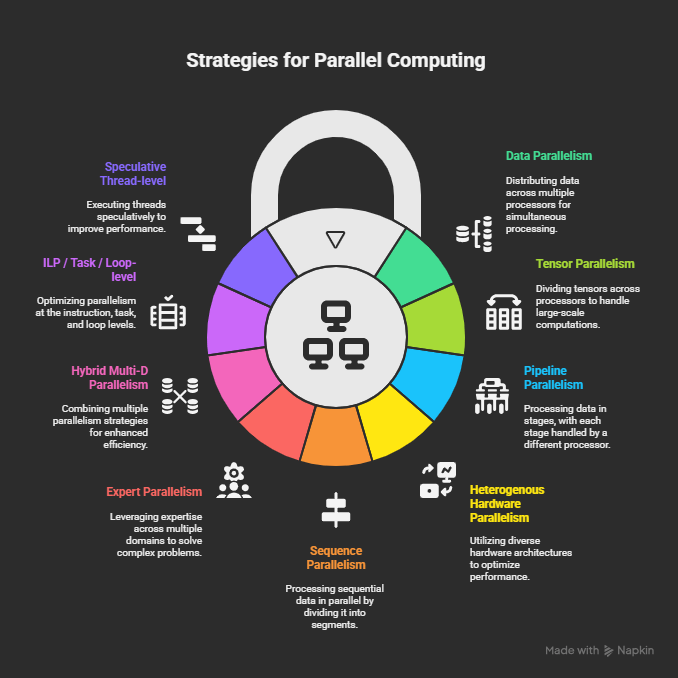
Data Parallelism
Data parallelism involves replicating the entire model on multiple processors and splitting the training data among them. Each processor independently processes a different batch of data, and periodically synchronizes model parameters (usually by all-reduce of gradients) to keep replicas consistent. This approach scales out training and is effective when the model fits in a single device’s memory, as it yields near-linear speedups with more data-parallel workers. Key benefits include straightforward implementation (minimal model modification) and high computation/communication overlap via efficient all-reduce algorithms in modern frameworks. Recent innovations in data parallelism are;
Zero Redundancy Optimizer (ZeRO) shards optimizer states and gradients across data-parallel workers to eliminate memory duplication, enabling training of trillion-parameter models with high throughput. Unlike traditional data parallelism, ZeRO reduces memory redundancy by ensuring that each device only stores a subset of these states, significantly lowering per-GPU memory usage. This allows for scaling to larger models and batch sizes without exceeding hardware memory limits.
Fully Sharded Data Parallelism (FSDP) in PyTorch is another innovation that partitions model states across GPUs, achieving linear memory savings and avoiding the need for complex 3D parallel layouts. FSDP shards model parameters, gradients, and optimizer states across data-parallel workers to reduce per-GPU memory load. It achieves training throughput comparable to traditional Distributed Data Parallel while enabling significantly larger models and near-linear scaling in FLOPS performance. This approach has made trillions-scale model training feasible on modest GPU memory by eliminating redundant copies.
Optimal Sharded Data Parallel (OSDP) – A research framework that generalizes ZeRO-based sharding by deciding per-operator whether to shard parameters. OSDP introduces operator splitting and fine-grained memory management to expand the decision space for sharding. It uses a search engine to find optimal parallelization plans, yielding up to 2.84X higher training throughput compared to state-of-the-art systems. This flexibility breaks previous all-or-nothing sharding limitations and adapts the data-parallel strategy to each layer’s characteristics for maximum efficiency.
Cyclic Data Parallelism: In this method, a new training method where micro-batches are processed sequentially with a uniform delay instead of simultaneously. This approach reduces activation memory peaks and balances gradient communication, resulting in more efficient training. When combined with Model Parallelism or ZeRO-DP, it lowers GPU requirements and replaces costly collective communications with point-to-point operations, showing strong results on CIFAR-10 and ImageNet.
Model Parallelism With Subnetwork Data Parallelism: This method introduce a distributed training method that reduces memory usage by training small, structured subnetworks of a large model independently on different workers. This avoids inter-node activation communication and keeps communication costs low and comparable to data parallelism. Their stochastic block dropping strategy, which favors subnetworks with skip connections, achieves 20–40% memory savings without sacrificing performance, outperforming previous width-wise approaches.
Overall, current research focuses on reducing communication and memory overhead in data parallelism – e.g. gradient compression techniques and adaptive all-reduce – to improve scalability on larger clusters.
Model Parallelism
Model parallelism refers to partitioning a neural network’s model across multiple processors, so that each handles only a portion of the model’s layers or parameters. A typical approach is layer-wise splitting: e.g. GPU 0 runs the first few layers, then forwards intermediate results to GPU 1 for the next layers, and so on.
This allows training of models too large for a single GPU’s memory. The downside is potential under-utilization – if done naively, only one partition is active at a time, causing others to idle and adding communication overhead. Modern techniques mitigate this via overlapping computation (see Pipeline Parallelism below) or intra-layer parallelism. One common form of intra-layer model parallelism is tensor slicing, where large weight matrices or tensor operations are split across devices (often called tensor parallelism, detailed next).
Model parallelism is applicable when a model’s layers or parameters cannot fit on one device, and it’s been essential in training multi-billion-parameter models (e.g. GPT-3 and beyond). Recent advances focus on making model partitioning more automated and efficient.
Mesh-TensorFlow can automatically find an optimal model parallel layout across many devices. Integration with memory optimizations (like activation checkpointing) and combination with other parallelism forms (data/pipeline) have been explored to maximize throughput.
SWARM Parallelism – A model-parallel training algorithm designed for heterogeneous, unreliable, and network-limited environments. Instead of requiring a tightly coupled GPU cluster, SWARM forms temporary randomized pipeline connections between distributed nodes which are dynamically rebalanced on failure. This approach enables training very large models on cheaper preemptible instances or across regions, by tolerating slow/failed nodes. The authors demonstrated training a 1B-parameter Transformer (13B effective with weight sharing) across preemptible T4 GPUs (≈200 Mb/s links), achieving robust throughput with minimal communication overhead. SWARM broadens access to large-model training beyond specialized supercomputers.
Tensor Parallelism
Tensor parallelism (also known as intra-layer model parallelism) is a specific form of model parallelism where the computations of a single layer (especially large matrix multiplications) are split across multiple processors. For example, a weight matrix might be partitioned column-wise or row-wise among GPUs; each GPU computes its part of the matrix multiply, and partial results are then aggregated. This effectively distributes the parameter tensor of a layer across GPUs, reducing per-GPU memory usage for model weights and activations.
By parallelizing the math of a layer, tensor parallelism can speed up training of very large layers and enable models whose individual layers wouldn’t fit in one GPU’s memory. The trade-off is the need for synchronization/communication between GPUs at each layer (to exchange partial outputs), which can become a bottleneck. Recent research has tackled this communication overhead.
Flash Communication proposes a low-bit compression of the messages exchanged in tensor-parallel inference, reducing intra-node communication time by >3X with negligible accuracy loss. Such approaches address the bandwidth bottleneck so that scaling efficiency improves when using many GPUs for one layer.
Megatron-LM Tensor Parallelism – First popularized in NVIDIA’s Megatron-LM (Shoeybi et al. 2019), tensor (model) parallelism remains a key technique in recent years. It partitions each layer’s weight matrices across multiple GPUs, so that matrix multiplications (e.g. in Transformer feed-forward or attention) execute in parallel on smaller shards. This reduces memory per GPU, allowing larger models to be trained, at the cost of inter-GPU communication to gather partial results. In 2023–2025, tensor slicing is ubiquitously employed in large language model training (often alongside data and pipeline parallelism) and has been optimized in frameworks like NeMo and DeepSpeed to minimize communication overhead. While not a brand-new method, continuous engineering (e.g. optimized all-reduce in NVIDIA NCCL) has pushed tensor-parallel scaling efficiency close to linear for multi-billion parameter models.
In practice, tensor parallelism is often used alongside data parallelism; libraries like NVIDIA Megatron-LM implement 1D and 2D tensor slicing of Transformer layers to allow training models with tens of billions of parameters. The past two years have also seen work on 2.5D and 3D tensor parallel partitioning (e.g. by Colossal-AI), which balance communication and computation by partitioning tensors in more complex ways. These developments collectively improve the viability of tensor parallelism for training extremely large neural networks by optimizing memory usage and communication overhead.
Sync-Point Drop for Efficient Tensor Parallelism: A new optimization method designed to reduce communication overhead during distributed inference of large language models using tensor parallelism. SPD works by selectively skipping synchronization steps on attention outputs, which are typically major contributors to latency. The approach involves modifying the model’s block structure to allow certain computations to proceed without requiring immediate communication between devices. Additionally, SPD applies its optimization more aggressively to attention blocks that are less sensitive to accuracy loss, helping to maintain model performance. In experiments with LLaMA2-70B across 8 GPUs, SPD reduced overall inference latency by approximately 20%, with less than 1% degradation in accuracy, offering a practical and scalable improvement for distributed inference systems.
Tensor-Parallelism with Partially Synchronized Activations: The paper introduces CAAT-Net (Communication-Aware Architecture for Tensor-parallelism), a method that reduces the communication overhead typically required for synchronizing activations in tensor-parallel training and inference of large language models. By making minor modifications to standard practices, CAAT-Net allows models to operate with significantly less synchronization. Experiments on 1B and 7B parameter models show a 50% reduction in tensor-parallel communication without compromising pretraining accuracy. Additionally, CAAT-Net improves the efficiency of both training and inference, highlighting its potential as a scalable solution for bandwidth-constrained environments.
Low-bit Communication for Tensor Parallel LLM Inference: This work addresses the growing communication overhead in tensor parallelism for large language model inference by introducing a novel quantization method. Unlike existing approaches, it targets the features that are actually communicated during tensor parallelism. By exploiting consistent outliers in these features, the method reduces the average communication precision from 16 bits to 4.2 bits, significantly lowering bandwidth requirements. Despite this reduction, it retains nearly all of the model’s original performance—achieving around 98.0% for Gemma 2 27B and 99.5% for LLaMA 2 13B across evaluated tasks—demonstrating its effectiveness for scalable LLM inference.
Pipeline Parallelism
Pipeline parallelism is a technique to split the sequence of model layers into stages placed on different processors, forming an assembly line for minibatch execution. Instead of one device waiting idle while another finishes its part of the network, pipeline parallelism breaks a batch into micro-batches and streams them through the pipeline. As soon as GPU 0 finishes micro-batch 1’s forward pass on layer 1, it sends it to GPU 1 and begins micro-batch 2; this overlapping means all pipeline stages can work in parallel on different micro-batches.
The benefit is much higher GPU utilization than naive model parallelism, especially for large batch sizes, since it reduces idle time. However, pipeline parallelism introduces pipeline bubbles – some stages are idle at the start and end of an iteration because they have no data yet or have finished early. There’s also complexity in scheduling the forward and backward passes of many micro-batches without interference. Recent research has produced new pipeline schedules to minimize idle bubbles.
1F1B (One-Forward-One-Backward) scheduling (e.g. in Microsoft’s DeepSpeed), which alternates sending forward and backward passes to partially overlap them, reducing bubble time. It issues one instruction from a thread (forward) and then selects another from a different thread (backward), promoting fairness and efficient resource use. This helps balance throughput while avoiding thread starvation.
An even more advanced approach is Bidirectional Pipeline Parallelism. DualPipe, introduced in 2024, is a bidirectional pipeline algorithm that feeds micro-batches from both ends of the model pipeline simultaneously. By overlapping the forward pass of newer micro-batches with the backward pass of earlier ones, DualPipe achieves full overlap of forward and backward computation with communication, drastically reducing idle bubbles. It essentially enables two “waves” (forward wave and backward wave) to propagate in opposite directions along the pipeline, keeping all stages busy. DualPipe’s design led to significantly higher utilization in large Transformer training – tests from DeepSeek report faster iteration times and better efficiency compared to conventional pipeline schedules.
Another development is Breadth-First Pipeline Parallelism, a novel scheduling strategy that optimizes the mix of pipeline and data parallelism. It keeps per-GPU batch size small (to save memory) while still achieving high utilization via pipeline parallelism. In experiments, Breadth-First Pipeline Parallelism improved training throughput by up to 43% for a 52B-parameter model compared to the Megatron-LM approach, reducing training time and cost accordingly. These advances show that pipeline parallelism remains an active area, with research focusing on smarter scheduling and combining pipeline stages with other parallelism forms to maximize efficiency.
BPipe (Kim et al., 2023) – A novel pipeline schedule framework that addresses the activation memory bottleneck in 1F1B (one-forward-one-backward) pipelines. BPipe introduces memory-efficient “building blocks” that control the lifespan of activations in the pipeline. By transferring activation data between stages based on memory imbalances, it cuts peak activation memory to 1/2 (or even 1/3) of 1F1B without throughput loss. This approach nearly eliminates pipeline bubble overhead while maintaining low memory usage. Experiments in pure pipeline setups show 7%–55% higher throughput than 1F1B, and about 16% throughput gain in large-scale hybrid parallel training of language models. BPipe’s controllable memory scheduling enables training with smaller batch-per-GPU or longer sequences by alleviating memory pressure in pipeline-parallel training.
MPMD Pipeline Parallelism: A system designed to efficiently scale the training of large deep learning models through flexible pipeline parallelism. It provides a user-friendly programming model that supports custom pipeline schedules for gradient accumulation. It automatically handles the distribution of pipeline stages across nodes and infers the necessary communication between them. It includes a MPMD runtime for asynchronous execution of SPMD tasks. Compared to traditional SPMD configurations, JaxPP significantly improves hardware utilization, making it a practical solution for large-scale model training.
Sequence Parallelism
Sequence parallelism is a newer parallelization technique that has emerged to handle very long input sequences in Transformer models. The idea is to split each input sequence across multiple GPUs (along the sequence length dimension) so that each GPU processes a different segment of the sequence in parallel. This is crucial for training Large Language Models with extended context windows (e.g. 8K, 32K tokens or more), because the memory and compute cost of attention scales quadratically with sequence length.
By sharding a long sequence into shorter chunks per GPU, sequence parallelism amortizes memory usage per device and makes long-context training feasible. For example, one GPU might handle tokens 0-1023, while another handles tokens 1024-2047-… etc, and they communicate just enough to compute attention across the split. Sequence parallelism can be seen as analogous to data parallelism, but splitting within a single sequence rather than across different sequences. Early implementations (e.g. DeepSpeed-Ulysses) assumed all sequences are of equal length and used a fixed splitting strategy, which can lead to inefficiencies when real training data has varied sequence lengths.
New approaches introduce adaptive sequence parallelism: for each batch, they choose an optimal way to shard sequences based on length distribution.
FlexSP (Wang et al., 2024) is one such system that treats sequence parallelism configuration as an optimization problem. It monitors the variability in sequence lengths and assigns an optimal combination of scattering strategies for each training step, rather than one static policy. By solving a cost minimization (via linear programming) for how to split each sequence, FlexSP achieved up to ~1.98X training throughput improvement over state-of-the-art static methods on long-context LLM training.
Other works like LightSeq and Seq1F1B have explored efficient pipeline+sequence parallel hybrids for long sequences. The applicability of sequence parallelism is primarily in NLP (or other sequence tasks) where context lengths are growing; it’s an important fourth dimension of parallelism to complement data, model, and pipeline parallel strategies in modern LLM systems.
Expert Parallelism
Expert parallelism is a parallelization strategy specific to Mixture-of-Experts (MoE) neural networks. In an MoE model, only a subset of “expert” sub-networks (feed-forward blocks) are active for any given input token, which enables extremely large model capacity without proportional increase in computation. However, MoE models require distributing many experts across multiple devices – this is where expert parallelism comes in. It assigns different expert blocks to different GPUs, and at runtime each token is routed (via a gating function) to the appropriate expert’s GPU for processing.
By parallelizing experts, one can scale MoE models to have hundreds or thousands of experts that collectively span many GPUs. The challenge is that during training or inference, tokens must be redistributed (all-to-all communication) so that each GPU receives the tokens destined for its local experts. This communication can be intensive and imbalance can occur if some experts get many more tokens than others. In fact, the all-to-all exchange in expert parallelism can dominate total time (often 50% of iteration time) if not optimized.
Recent research has tackled two key issues: communication overhead and load imbalance. On the communication side, techniques like hierarchical all-to-all and overlapping have been proposed.
A 2024 innovation, for example, is ScMoE (Shortcut-connected MoE) which redesigns the MoE layer to decouple communication and computation. It introduces a shortcut connection so that communication of token activations can be started earlier and fully overlapped with computation. ScMoE achieves 100% overlap of communication with computation, significantly speeding up training and inference of MoE models. Experiments showed it can surpass the throughput of standard MoE (top-2 gating) while maintaining model quality, effectively eliminating the sequential comm-compute dependency bottleneck. For the load imbalance issue, new dynamic load balancing methods have emerged. One approach is to monitor and replicate “hot” experts that consistently receive more tokens.
DeepSeek’s training framework introduced Expert Parallel Load Balancer (EPLB) in 2025, which tracks the utilization of each expert and dynamically replicates overloaded experts onto other GPUs to share the work. By adding extra copies of the busiest experts (and smartly placing those copies on under-utilized devices), EPLB ensures no single GPU becomes a bottleneck due to hosting a disproportionately popular expert. It uses heuristics to decide replication and placement, even adjusting over time as different experts become more or less active.
Another recent work, MoETuner (2024), formulated an integer programming solution to optimally assign experts to GPUs a priori given expected token routing patterns. By clustering certain experts on the same GPU to minimize cross-GPU routing and balancing token loads, MoETuner demonstrated ~9% single-node and ~17% multi-node inference speedups for MoE serving.
Pro-Prophet (2024) – A systematic load-balancing framework for Mixture-of-Experts (MoE) models, which introduce expert parallelism on top of data/model parallelism. MoE layers can suffer severe load imbalance – e.g. only a few expert GPUs get most of the tokens – leading to poor utilization. Pro-Prophet tackles this with a two-part solution. One is a planner that profiles the dynamic token-to-expert routing and selects lightweight expert placement strategies to redistribute load, minimizing extra communication; and then a scheduler that overlaps communication with computation by speculatively transferring parameters of likely-overloaded experts ahead of time. In tests across four clusters and five MoE models, Pro-Prophet achieved up to 2.66X training speedup over DeepSpeed-MoE and FasterMoE framework. It also improved load balance (measured by token distribution) by up to 11X compared to prior methods. This demonstrates a significant advance in efficiently training MoE-based LLMs via expert parallelism without the usual performance hits from imbalance or auxiliary balancing losses.
Expert parallelism enables the scaling of MoE models by distributing experts across hardware, and the latest research focuses on making this distribution efficient via overlapping communication and balancing workload to fully exploit the benefits of MoE’s sparse computation.
3D and 4D Parallelism
“3D parallelism” refers to hybrid strategies that combine three forms of parallelism simultaneously, typically to train very large models. In the context of large Transformer models, 3D parallelism usually means using Data Parallel (DP) + Pipeline Parallel (PP) + Tensor Model Parallel (TP) together. Each approach addresses a different bottleneck (data parallel handles scale of data and batch size, pipeline parallel handles model depth, tensor parallel handles layer width). By integrating them, one can spread a model and its training across hundreds or thousands of GPUs.
For example, Megatron-LM’s approach to training a 1+ trillion-parameter model involves splitting the model into pipeline stages, splitting each layer’s weights across multiple GPUs (tensor parallel), and also replicating the whole pipeline across data-parallel groups for different data shards – this is a classic 3D parallel setup. The primary benefit of 3D parallelism is improved memory and compute scaling: one dimension (model splitting) reduces per-GPU memory usage, another (pipeline) increases utilization, and the third (data) provides additional speedup and memory redundancy removal (especially when combined with sharding like ZeRO). Microsoft’s DeepSpeed demonstrated that such 3D combinations, coupled with ZeRO optimizations, can efficiently train models with trillions of parameters.
Building on 3D, the term “4D parallelism” is used when a fourth parallelization dimension is introduced. What this fourth dimension is can vary by context. In long-context language model training, a 4th dimension might be Sequence (Context) Parallelism (SP) added to DP+PP+TP. In Mixture-of-Experts models, the 4th dimension is naturally Expert Parallelism (EP) added on top of DP+TP+(sometimes PP). In either case, 4D parallelism means sharding the workload in four independent ways to tackle different scaling challenges.
For instance, training a massive 405B-parameter LLaMA model reportedly used 4D parallelism: combining data, pipeline, tensor, and expert parallelism to leverage thousands of GPUs efficiently. Similarly, recent work on workload-balanced training explicitly addresses imbalances that arise in 4D parallel schemes (e.g. unequal token loads across pipeline and sequence shards) and offers solutions like adaptive sequence sharding and packing. The complexity of managing 4D parallelism is high – it requires careful coordination between all levels – but when done right, it yields unprecedented model scales.
For example, DeepSpeed-TED (ICS 2023) combined data, tensor, and expert parallelism (a “3D” in that context) to train MoE models with 4–8X larger dense backbone (base model) than previously possible, by resolving new bottlenecks that appear when mixing these parallel modes. We can expect 4D strategies to become more common as models push toward multi-trillion parameters or extremely long sequences, with research focusing on automated parallelism planners and balancing techniques to fully utilize hardware in these multi-dimensional parallel setups.
Merak (IEEE TPDS 2023) – An automated framework for 3D parallelism that coordinates data, pipeline, and tensor parallel strategies. Merak features an automatic model partitioner (graph sharding algorithm) and a high-performance 3D runtime. It introduces techniques like shifted critical-path pipeline schedules (to maximize compute utilization per stage), stage-aware recomputation (to use idle memory for saving checkpointed activations), and sub-pipelined tensor parallelism (to overlap communication with computation). In multi-node trials up to 64 GPUs, Merak delivered 1.4X–1.6X faster training throughput than baseline 3D parallel frameworks for models ranging from 1.5B to 20B parameters. Crucially, Merak achieves these gains with minimal code changes by the user, making efficient 3D parallel training more accessible. It represents a step toward automating the complex hyper-parameter tuning of hybrid parallelism layouts for different model sizes.
Breadth-First Pipeline Parallelism
Breadth-First Pipeline Parallelism is a recently proposed pipeline schedule (2023) that optimizes how pipeline parallelism interacts with data parallelism and micro-batch sizing. Traditional pipeline parallelism (like GPipe) often requires large batch sizes per GPU to keep the pipeline full, which can increase memory usage and latency. The breadth-first approach instead uses smaller batch sizes per GPU (beneficial for memory and convergence) while still keeping GPUs busy by increasing pipeline parallel degree.
In essence, it processes many micro-batches across the pipeline “breadth-wise” before accumulating gradients, as opposed to a purely depth-first execution of one batch at a time. According to Joel Lamy-Poirier’s work, Breadth-First Pipeline Parallelism achieved up to 43% higher throughput on a 52B model compared to Megatron-LM’s schedule when using small batches. It effectively lowers training time and cost by combining high GPU utilization with the memory savings of small per-GPU batches. The technique also leveraged fully sharded data parallelism (ZeRO) to further reduce memory per GPU, which allowed the pipeline to operate with minimal idle time despite the smaller batch sizes. This approach is particularly applicable when hardware memory is a limiting factor – it lets you pipeline through many micro-batches without blowing up memory on each device.
The results indicate that breadth-first scheduling can outperform other pipeline strategies at lower batch sizes, making large-model training more efficient in regimes where batch scaling is limited by hardware or optimization considerations. This is a good example of how systems-level tuning of parallel execution (not just algorithmic improvements in models) can yield significant performance gains in deep learning training.
Instruction-Level Parallelism (ILP)
Instruction-Level Parallelism refers to the ability of a CPU to execute multiple machine-level instructions simultaneously by leveraging independent operations within a single thread. Modern processors achieve ILP through pipelining, superscalar execution, and out-of-order scheduling. Essentially, the processor’s hardware dynamically finds instructions that don’t depend on each other and issues them to different execution units in the same clock cycle.
For example, while one arithmetic instruction is waiting for a memory load to complete, another independent arithmetic instruction might be executed in parallel in a separate functional unit. Techniques like super-scalar pipelines (multiple instructions per cycle) and out-of-order execution (reordering instructions to avoid stalls while preserving program correctness) dramatically increase ILP beyond the old one-instruction-per-cycle model. This form of parallelism is invisible to the programmer – it’s exploited by the CPU’s microarchitecture. The benefit of ILP is higher single-thread performance: by overlapping instruction execution, CPUs complete more instructions in a given time. Over the past couple of years, ILP has continued to be a cornerstone of CPU improvements, although we are in a regime of diminishing returns due to dependencies and branch limits (often referred to as hitting the “ILP wall”). Recent research and processor designs still push ILP via wider issue widths, deeper pipelines, and better speculation.
For instance, Apple’s M-series chips and the latest x86-64 microarchitectures can decode and dispatch up to 8–10 micro-ops per cycle, and use sophisticated branch prediction and speculative execution to keep pipelines full, illustrating state-of-the-art ILP in practice (though details come from industry rather than open publications). Academic work around ILP in the last two years often intersects with security (mitigating speculative execution vulnerabilities like Spectre) and power efficiency (making out-of-order execution more energy-efficient). In summary, ILP is a mature domain: the technical breakdown includes pipelining (overlapping instruction stages), multiple issue (executing independent instructions concurrently), and speculation (guessing future instruction flow to execute ahead). These techniques collectively allow a single thread to utilize parallel hardware resources, and ongoing research refines these mechanisms to improve performance under modern constraints.
Constable (ISCA 2024) – A microarchitectural innovation that increases ILP by eliminating redundant load executions. Load instructions often form serializing dependencies in out-of-order CPUs (waiting on memory and tying up resources). Constable identifies “likely-stable” loads – those that repeatedly fetch the same value from the same address – and skips executing future occurrences of those loads until the data actually changes. It leverages hardware to track when a load’s source memory or register is modified and only then re-enables the load’s execution. By mitigating both data dependence and resource occupancy of invariant loads, Constable boosted SPEC CPU performance by ~5.1% on average (8.8% with SMT) over an aggressive baseline that already had memory dependency handling. It also reduced core dynamic power by ~3.4%. Notably, combining Constable with a state-of-art load-value predictor yielded an additional performance gain (~3–7% beyond value prediction alone). This design, which earned Best Paper at ISCA 2024, shows that even in modern CPUs, intelligent speculation to remove unnecessary instruction work (in this case, skipping loads that predictably hit in cache with the same data) can translate to tangible efficiency gains in both speed and power.
Loop-Level and Task Parallelism
Loop-level parallelism is a high-level parallelization approach where individual iterations of a loop are executed concurrently on multiple processing units, assuming the iterations are independent. This is a common scenario in scientific computing and data processing: e.g., applying the same operation to each element of a large array can be parallelized by splitting the loop iterations among threads or GPUs. The benefit is straightforward scaling for data-parallel tasks – if you have N iterations and P threads, ideally each thread can perform N/P iterations simultaneously, greatly reducing runtime.
A key technical aspect is ensuring there are no loop-carried dependencies (or handling them with synchronization if they exist) so that iterations indeed can run in parallel. In the past two years, research in this area has been incremental, focusing on compiler analyses to identify more opportunities for parallelizing loops (even irregular ones) and on runtime scheduling to handle load imbalance. For example, techniques like polyhedral compilers and dependency analysis improvements allow automatic parallelization of loops that were previously hard to analyze. Additionally, in GPU computing, loop unrolling and distributing work across many cores (SIMT style) is essentially loop-level parallelism at scale; new GPU programming models (like NVIDIA’s Hopper architecture with dynamic parallelism) provide more flexibility for loop parallelization.
OMP4Py (Python OpenMP, 2024) – An effort to bring OpenMP-style parallel loops and tasks to the Python ecosystem. With the Python interpreter moving toward removing the Global Interpreter Lock (GIL) in version 3.13, OMP4Py is a research prototype that implements the OpenMP API purely in Python, allowing developers to annotate loops with parallel directives much like in C/C++. This enables Python code to spawn multiple threads and divide work across them for CPU-bound tasks, using familiar pragma-based patterns (e.g. #pragma omp for). The authors demonstrate that, once the GIL is disabled, a high-level language can still exploit multi-core CPUs effectively
Task parallelism, on the other hand, refers to parallelizing units of work that may be larger or more heterogeneous than loop iterations – these are often independent functions or computational tasks that can run concurrently. Instead of doing the same operation on different data (as in data parallel loops), task parallelism might involve different operations or stages of a pipeline running in parallel on different cores or machines. Modern programming models (such as Cilk, TBB, or task libraries in OpenMP and Python’s concurrent.futures) allow developers to express parallel tasks and let a scheduler distribute them.
The technical challenges include dealing with dependencies between tasks (often represented as a DAG – directed acyclic graph of tasks) and scheduling tasks efficiently to avoid idle cores. In the last couple of years, the research focus has been on dynamic task scheduling and load balancing in task-parallel runtime systems. For instance, work stealing schedulers and graph-based execution engines have been refined to handle fine-grained tasks with low overhead. A prominent area is task-based parallelism in HPC (e.g., the PaRSEC and StarPU frameworks) where instead of parallelizing one loop at a time, an entire algorithm is expressed as a graph of tasks with dependencies – the runtime then executes tasks in parallel respecting those dependencies. Loop-level vs task parallelism: Loop-level is a subset of task parallelism where tasks happen to be uniform and structured (the loop iterations), whereas general task parallelism covers arbitrary independent units of work.
Both see continued use: for embarrassingly parallel workloads, loop parallelism (possibly with SIMD as well) is extremely effective; for more complex workflows, task parallelism yields better flexibility. Recent academic publications (2023–2025) in this space include improvements to dependency-aware scheduling (minimizing synchronization overhead) and integration with asynchronous programming models (like combining async/await with task parallel libraries). Overall, loop-level and task parallelism remain fundamental techniques, with ongoing refinements rather than radical changes – the emphasis is on making parallel programming easier (through high-level frameworks) and more efficient (through smarter runtimes and compilers).
Speculative and Thread-Level Parallelism
Thread-level parallelism (TLP) refers to exploiting parallelism by running multiple threads or processes simultaneously, each executing a portion of a workload. This is coarse-grained parallelism at the level of independent threads (or tasks), as opposed to fine-grained ILP within one thread. There are two contexts to consider: one is explicit multi-threading in software (where the programmer or runtime divides work among threads), and another is hardware multi-threading (such as Simultaneous MultiThreading, SMT, where a CPU core runs instructions from multiple threads at once to increase utilization).
In general, thread-level parallelism improves throughput and resource utilization by having multiple streams of instructions in flight. For example, a web server might handle different client requests on different threads in parallel. Many modern CPU cores support hardware TLP by having multiple register sets and interleaving execution of two (or more) threads – this can hide latency (one thread can use the ALU while another waits for memory) and is utilized in architectures like Intel’s Hyper-Threading. The benefit of TLP is seen in any application that can be decomposed into concurrent tasks or that operates on independent data partitions. Over the past few years, enabling high-performance thread-level parallelism has involved everything from improved language support (e.g. better thread libraries and concurrency features in C++20, Rust, etc.) to OS-level enhancements (like more efficient context switching and scheduling for many-core systems).
Speculative parallelism is a technique used when the compiler or runtime cannot determine for sure that a section of code can be parallelized safely, but it guesses (speculates) that running it in parallel will not cause conflicts. If the speculation is correct, you gain speed-up by having executed in parallel; if it’s wrong (e.g. there was a hidden dependency), the system must roll back or fix up the results. This concept is often implemented as Thread-Level Speculation (TLS) or speculative multithreading. Essentially, the processor/runtime will execute what would normally be sequential code on multiple threads in parallel, under the hood, and monitor for any memory conflicts or data dependency violations. If none occur, great – the code ran faster in parallel. If a violation does occur, the speculative threads are aborted or their results discarded, and the code may be re-executed serially (or the conflicting thread waits). Thread-Level Speculation utilizes speculative parallelization to accelerate hard-to-parallelize serial codes on multi-cores. It’s like optimistic concurrency in databases but for code execution: proceed in parallel assuming it’s safe, and if not, undo and serialize. The benefit is potentially significant speed-ups on code that is logically sequential (due to unknown dependencies) but often doesn’t actually conflict in practice.
Research in speculative parallelism saw a resurgence with heterogeneous multi-cores. For example, LitTLS (2023) introduced a lightweight TLS design for ARM big.LITTLE systems, showing that even small “little” cores can be used to speculatively run ahead on code and speed up a program by ~2.9X over a single core. They achieved this with minimal hardware overhead by clever use of cache for versioning and a centralized structure for dependency checking, addressing prior TLS designs’ complexity. This demonstrates continued academic interest in making speculation more efficient and practical. Another angle is compiler techniques to automatically identify likely-independent code sections (like loops with possible pointer aliasing) and insert TLS instrumentation to run them in parallel. While not mainstream in general-purpose computing yet, TLS has been used in research prototypes and some specialized processors to great effect.
In summary, thread-level parallelism (non-speculative) is ubiquitous in modern computing – it’s the basis of multi-core performance scaling. Speculative parallelism augments this by taking code that isn’t clearly parallel and attempting to run it concurrently anyway, correcting if necessary. The past two years of work in this realm continue to refine how we can get more parallel speed-up out of sequential code, with a focus on reducing overhead (so that speculation gains outweigh the costs) and expanding hardware support in an era where single-thread gains are hard to come by. This is an exciting complement to traditional parallelization: if successful, speculative execution can extract parallel performance from workloads that humans or compilers find difficult to manually parallelize, thereby further leveraging the multi-core and many-core hardware we have today.








.png)


