Democratizing GenAI by Commoditizing It
We do this by enabling enterprises, startups, and developers to have their own OpenAI-equivalent compound AI systems, models, and agents that can work on commodity hardware at a fraction of the cost.


Generative AI is the key to solving some of the world’s biggest problems, such as climate change, poverty, and disease. It has the potential to make the world a better place for everyone.
-Mark Zuckerberg


Back in the mainframe era, software applications faced high hardware dependency, hefty costs, and limited scalability. However, operating systems like Linux and Windows eventually solved these problems by bridging the gap between hardware and software. Today, generative AI is encountering similar hurdles—high costs, high hardware dependency, and scalability issues. So yes, we are kind of back in the mainframe era all over again.

We are on a mission to democratize access to generative AI, making it practical, affordable, profitable, and scalable for everyone. To achieve this, we’re reengineering the fundamentals of GenAI systems, from runtime environments to model architectures to agent frameworks. We make GenAI portable, scalable, and independent of specialized hardware.

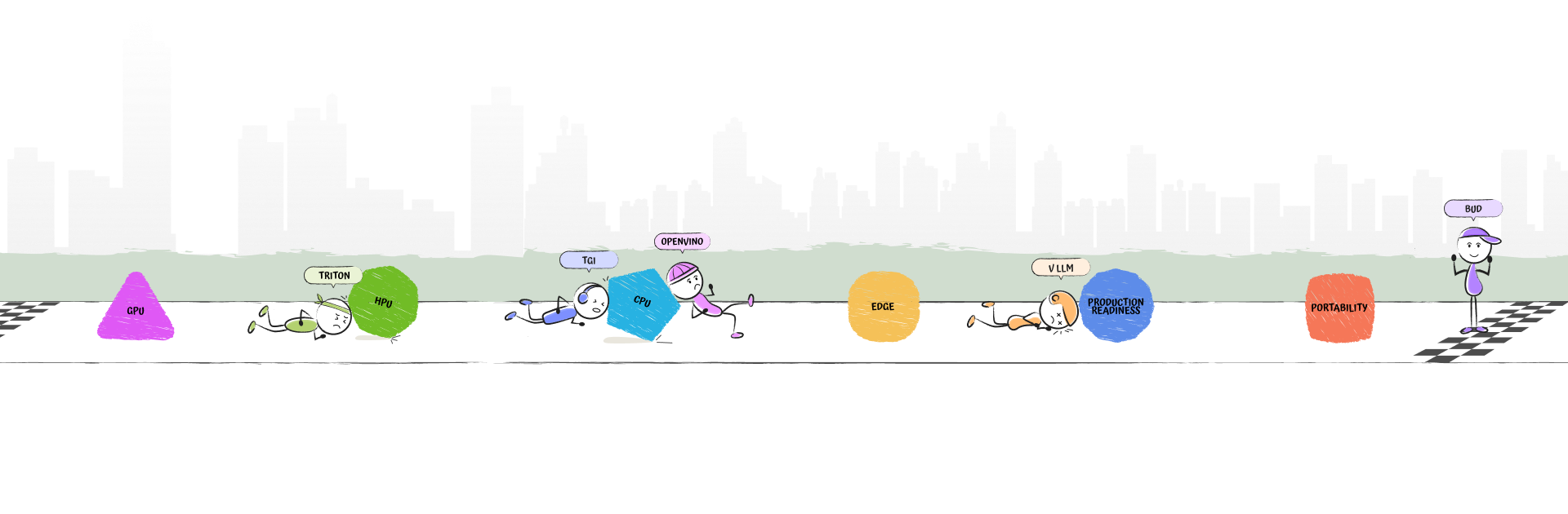
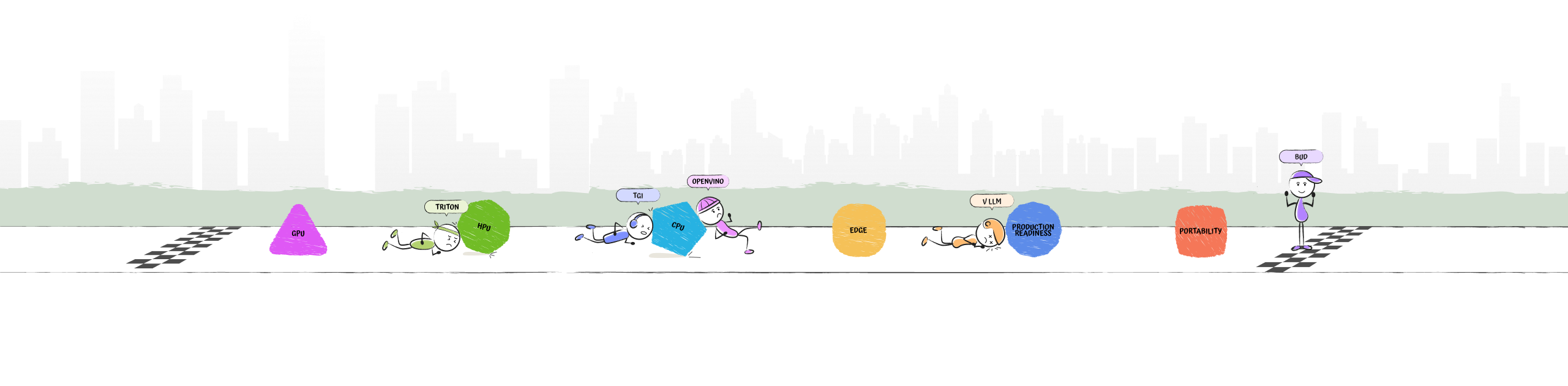
As the first step toward our mission, we have created the Bud Inference Engine, a GenAI runtime and inference software stack that delivers state-of-the-art performance across any hardware and operating system. It reduces the Total Cost of Ownership (TCO) of GenAI solutions by up to 55 times and ensures production-ready deployments on Intel CPUs, Xeons, Gaudis, NPUs, and GPUs. Bud Runtime delivers GPU-like performance for GenAI solutions using CPUs.
Bud Runtime achieves GPU-like throughput, latency, and scalability on CPUs, delivering state-of-the-art performance and optimizations across diverse hardware platforms. It reduces the Total Cost of Ownership (TCO) of GenAI solutions by up to 55 times, ensuring production-ready deployments on CPUs, NPUs, HPUs, and GPUs.
All experiments with LaMa 2 7B
[Uses a LLaMa-2 7B with FP16 on GPUs & BF16 on CPUs, without using optimisations that require fine tuning or pruning like Medusa, Eagle, speculative decoding]

Case Studies
Case Studies on How Bud Makes GenAI More Practical, Profitable, and Scalable.


Driving Enterprise RAG Innovation with Intel® Xeon® Processors
The chatbot solution has demonstrated superior performance compared to leading cloud-based solutions like Google Gemini Advanced, ChatGPT Plus, and Perplexity.


Benchmarking the Indus Language Model on Intel® AI Hardware
The Indus Language Model has undergone extensive benchmarking on the Intel platform, demonstrating robust performance across several critical areas.

Enhancing LLM inference performance on Intel CPUs
The integration led to a remarkable enhancement in LLM performance on CPUs, increasing throughput from 9 tokens per second to an impressive 520 tokens per second.

Benchmarking Mistral 7B Inference performance on GPUs
Our works are a blend of innovative thinking and practical solutions, ensuring they are both
Driving Enterprise RAG Innovation with Intel® Xeon® Processors
The chatbot solution has demonstrated superior performance compared to leading cloud-based solutions like Google Gemini Advanced, ChatGPT Plus, and Perplexity.
Benchmarking the Indus Language Model on Intel® AI Hardware
The Indus Language Model has undergone extensive benchmarking on the Intel platform, demonstrating robust performance across several critical areas.
Enhancing LLM inference performance on Intel CPUs
The integration led to a remarkable enhancement in LLM performance on CPUs, increasing throughput from 9 tokens per second to an impressive 520 tokens per second.
Research & Innovations
Deep dive into groundbreaking research and innovations shaping the future of GenAI

Intellecta Cognitiva: A Comprehensive Dataset for Advancing Academic Knowledge and Machine Reasoning
With a composition of 11.53 billion tokens, integrating 8.01 billion tokens of synthetic data with 3.52 billion tokens of rich textbook data, Intellecta is crafted to foster advanced reasoning and comprehensive educational narrative generation.

Inference Acceleration for Large Language Models on CPUs
In this paper, we explore the utilization of CPUs for accelerating the inference of large language models.

Efficient Hybrid Inference for LLMs: Reward-Based Token Modelling with Selective Cloud Assistance
This method not only reduces the traffic to the cloud LLM, thereby lowering costs, but also allows for flexible control over response quality depending on the reward score threshold.

Accelerating Embedding Models Inference and Deployments
Bud Ecosystem, with its universal Inferencing engine, maximizes the power of Intel® Xeon® processors to drive high performance, production-ready, andcost-efficient GenAI solutions.
Intellecta Cognitiva: A Comprehensive Dataset for Advancing Academic Knowledge and Machine Reasoning
With a composition of 11.53 billion tokens, integrating 8.01 billion tokens of synthetic data with 3.52 billion tokens of rich textbook data, Intellecta is crafted to foster advanced reasoning and comprehensive educational narrative generation.
Inference Acceleration for Large Language Models on CPUs
In this paper, we explore the utilization of CPUs for accelerating the inference of large language models.
Efficient Hybrid Inference for LLMs: Reward-Based Token Modelling with Selective Cloud Assistance
This method not only reduces the traffic to the cloud LLM, thereby lowering costs, but also allows for flexible control over response quality depending on the reward score threshold.
Blogs
Exploring the latest GenAI Innovations
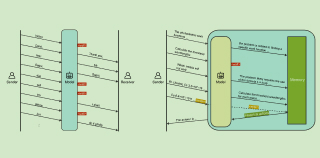
Low latency LLMs with simultaneous inference
Lossless Self-Speculative Decoding via Double Early Exiting
Fast yet Safe: Early-Exiting with Risk Control
Efficient Expert Pruning with Sparse Mixture-of-Experts
Low latency LLMs with simultaneous inference
Lossless Self-Speculative Decoding via Double Early Exiting
Fast yet Safe: Early-Exiting with Risk Control
News and Updates
What’s new? We’ve got some exciting developments to share!

Bud Ecosystem wins Breakthrough Innovation award from Intel Corporation
Bud Ecosystem Inc. announced today that Intel Corporation has recognized the organization with an Intel Partner Award in the category of Breakthrough Innovation - ISV.

Intel and Bud Ecosystem Forge Strategic Partnership
The companies have signed a Memorandum of Understanding to integrate Bud Ecosystem's GenAI software stack with Intel processors, enabling cost-effective GenAI deployment for enterprises.

Intel, Tech Mahindra, and Bud Ecosystem Collaborate on...
In a joint effort to enhance natural language processing for Hindi and its dialects, Intel, Tech Mahindra, and Bud Ecosystem have collaborated on Project Indus, a
Bud Ecosystem wins Breakthrough Innovation award from Intel Corporation
Bud Ecosystem Inc. announced today that Intel Corporation has recognized the organization with an Intel Partner Award in the category of Breakthrough Innovation - ISV.
Intel and Bud Ecosystem Forge Strategic Partnership
The companies have signed a Memorandum of Understanding to integrate Bud Ecosystem's GenAI software stack with Intel processors, enabling cost-effective GenAI deployment for enterprises.
Intel, Tech Mahindra, and Bud Ecosystem Collaborate on...
In a joint effort to enhance natural language processing for Hindi and its dialects, Intel, Tech Mahindra, and Bud Ecosystem have collaborated on Project Indus, a
GenAI Made Practical, Profitable and Scalable!




Runtime Inference Engine
Models
Case studies
Research & Thoughts
Blogs
News and Updates
© 2024, Bud Ecosystem Inc. All right reserved.